Unity Input Event Handlers - Or Adding Juice the Easy Way
/Need to add a little juice to your UI? Maybe your player needs to interact with scene objects? Or maybe you want to create a dynamic or customizable UI? This can feel hard or just plain confusing to add to your project. Not to mention a lot of the solutions out there are more complex than they need to be!
Using Unity’s Event Handlers can simplify and clean up your code while offering better functionality than other solutions. I’ve seen a lot of solutions out there to move scene objects, create inventory UI, or make draggable UI. Many or maybe most of those solutions are overly complicated because they don’t make full use of Unity’s event handlers (or the Pointer Event Data class).
Did I mention these handlers work with both the “new” and the “old” input systems. So learn them once and use them with either system.So let’s take a look at what they can do!
If you just want to see the example code, you can find it here on GitHub.
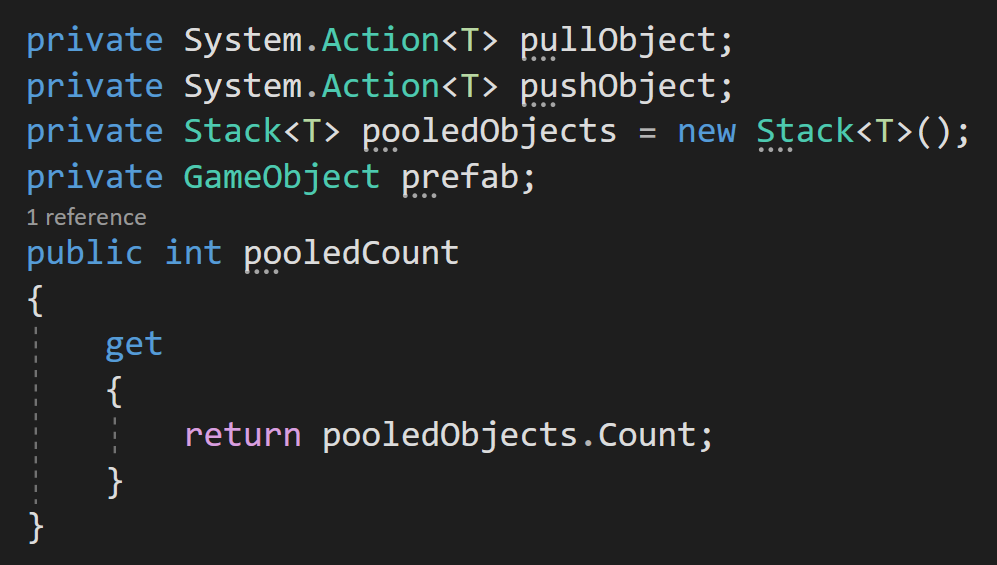
Input Event Handlers
Event handlers are added by including using UnityEngine.EventSystems and then implementing one or more of the interfaces. For example, IPointerEnterHandler will require an OnPointerEnter function to be added. No surprise - this function will then get called when the point enters (the rect transform of) the UI element.
The interfaces and corresponding functions work on scene objects. But! The scene will need a camera with a physics raycaster and more on that as we move along.
Below are the supported events (out of the box) from Unity:
IPointerEnterHandler - OnPointerEnter - Called when a pointer enters the object
IPointerExitHandler - OnPointerExit - Called when a pointer exits the object
IPointerDownHandler - OnPointerDown - Called when a pointer is pressed on the object
IPointerUpHandler- OnPointerUp - Called when a pointer is released (called on the GameObject that the pointer is clicking)
IPointerClickHandler - OnPointerClick - Called when a pointer is pressed and released on the same object
IInitializePotentialDragHandler - OnInitializePotentialDrag - Called when a drag target is found, can be used to initialize values
IBeginDragHandler - OnBeginDrag - Called on the drag object when dragging is about to begin
IDragHandler - OnDrag - Called on the drag object when a drag is happening
IEndDragHandler - OnEndDrag - Called on the drag object when a drag finishes
IDropHandler - OnDrop - Called on the object where a drag finishes
IScrollHandler - OnScroll - Called when a mouse wheel scrolls
IUpdateSelectedHandler - OnUpdateSelected - Called on the selected object each tick
ISelectHandler - OnSelect - Called when the object becomes the selected object
IDeselectHandler - OnDeselect - Called on the selected object becomes deselected
IMoveHandler - OnMove - Called when a move event occurs (left, right, up, down)
ISubmitHandler - OnSubmit - Called when the submit button is pressed
ICancelHandler - OnCancel - Called when the cancel button is pressed
Example Disclaimer
The examples below are intended to be simple and show what CAN be done. There will be edge cases and extra logic needed for most implementations. My hope is that these examples show you a different way to do some of these things - a simpler and cleaner way. The examples also make use of DoTween to add a little juice to the examples. If you’re not using it, I’d recommend it, but it’s optional all the same.
Also in the examples, each of the functions being used corresponds to an interface that needs to be implemented. If you have the function, but it’s not getting called double check that you have implemented the interface in the class.
UI Popup

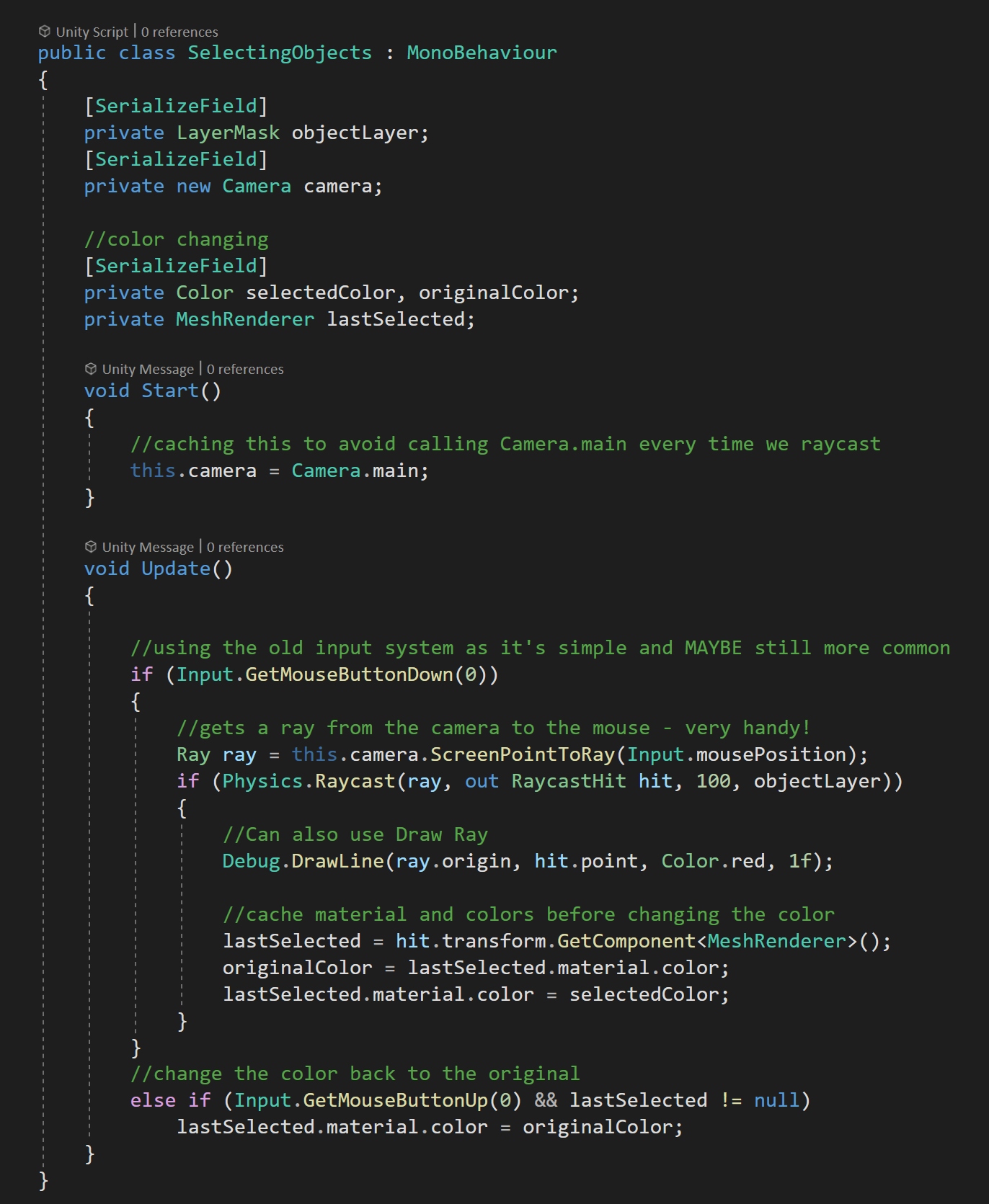
A simple use case of the event handlers is a UI popup to show the player information about an object that the pointer is hovering over. This can be accomplished by using the IPointerEnter and IPointerExit interfaces. For my example, I choose to invoke a static event when the pointer enters the object (to open a popup) and when the pointer exits (to close the popup). Using events has the added benefit that other systems beyond the popup menu can also be aware of the event/action - which is huge and can allow more polish and juice to be added. It also means that information about the event and the object can be passed with the event.
In my particular case, the popup UI element is listening to these events and since the PointerEventData is being passed with the event, the popup UI element can appear on-screen near the object. In my case rather than place the popup window at the same location as the pointer I’m using a small offset.

This code is placed on objects - to enable popup
Physics Raycaster
If you want or need the Event Handlers to work on scene objects (like the example above) you will need to add a Physics Raycaster to your camera.
This is pretty straight forward, with the possible exception of the layer mask. You will need to do some sorting of layers in your scene and edit the layer mask accordingly if you are getting unwanted interactions.
For example in my project game units have a “Unit Detection” object on them which includes a large sphere collider. This is used to detect opposing units when they get close. The “Unit Detection” object is on a different layer to avoid unwanted interactions between scene objects. In my case, I also wanted to turn off this layer in the physics raycaster layer mask - as the extra colliders were blocking the detection of the pointer on the small collider surrounding the actual unit.

This code is placed on the popup window itself
Drag and Drop
This came up in my Grub Gaunlet game from a tester. Originally I had buttons at the top that when you clicked them a new game element appeared in the middle of the screen. This worked and was fine for the game jam, but being able to drag and drop the object is more intuitive and feels a whole lot better. So how do you do that with a button (or image)? Three event handlers make this really easy.

This goes on the UI element and needs to have the prefab variable set in the inspector
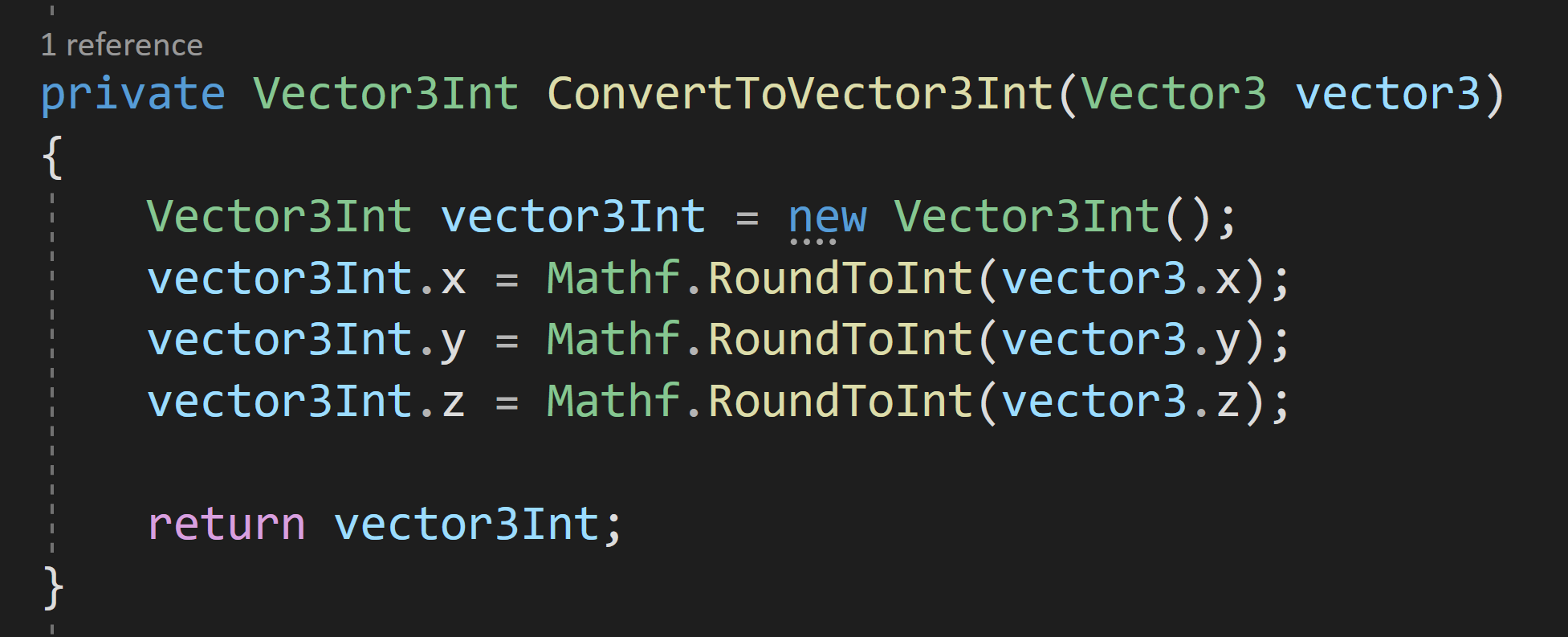
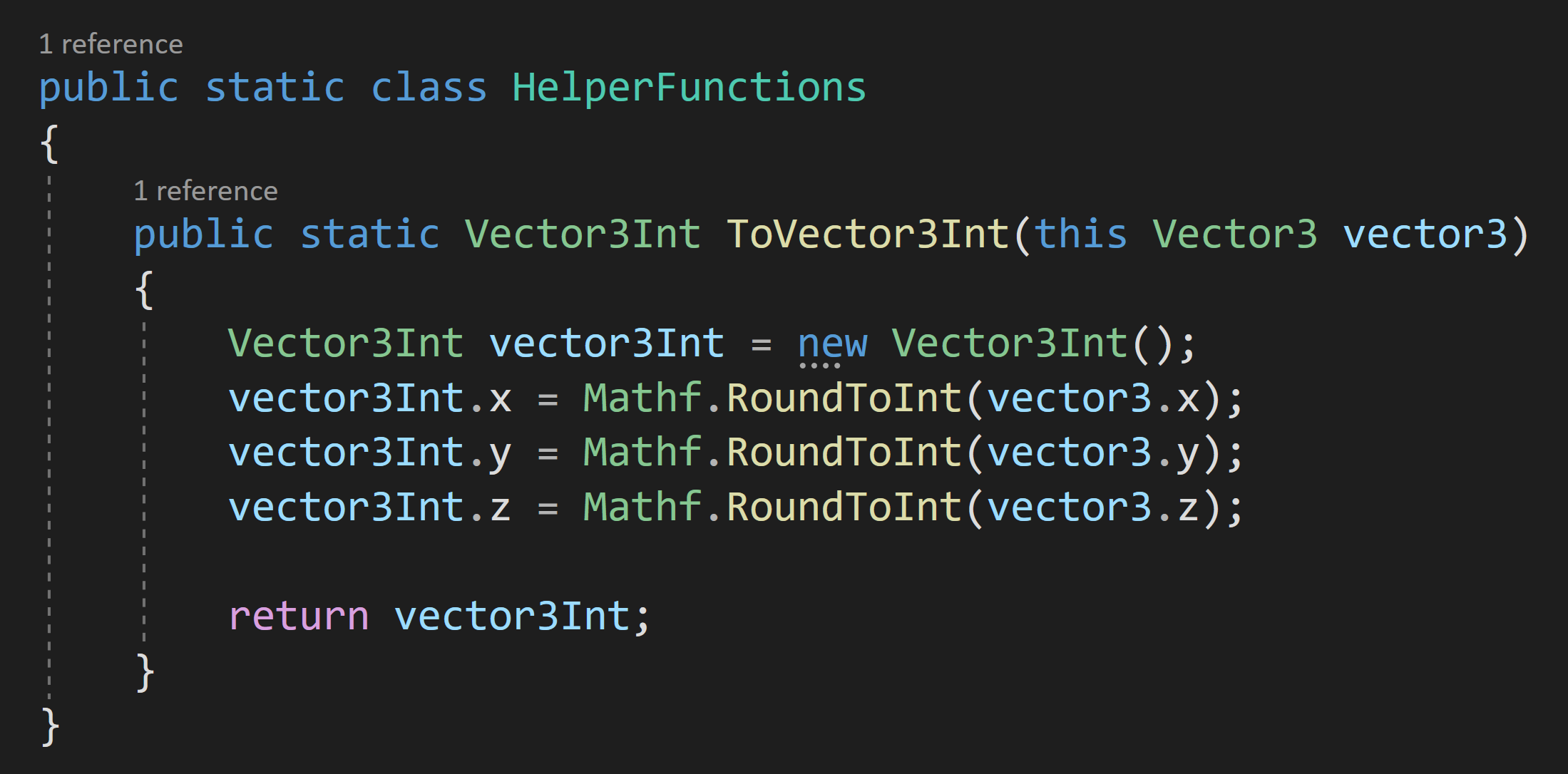
First, when the pointer is down on the UI element a new prefab instance is created and the “objectBeingPlaced” variable is set. Setting this variable allows us to track and manipulate the object that is being placed.
Then when the pointer comes up objectBeingPlaced is set to null to effectively place the object.
But the real magic here is in the OnUpdateSelected function. This is called “every tick” - effectively working as an update function. To my understanding, this is only called while the object is selected - so this is no longer called once the pointer is up or at the very least when the next object is selected. I haven’t done any testing, but I’d guess there are slight performance gains using this approach vs. an update function on each button. Not to mention this just feels a whole lot cleaner.
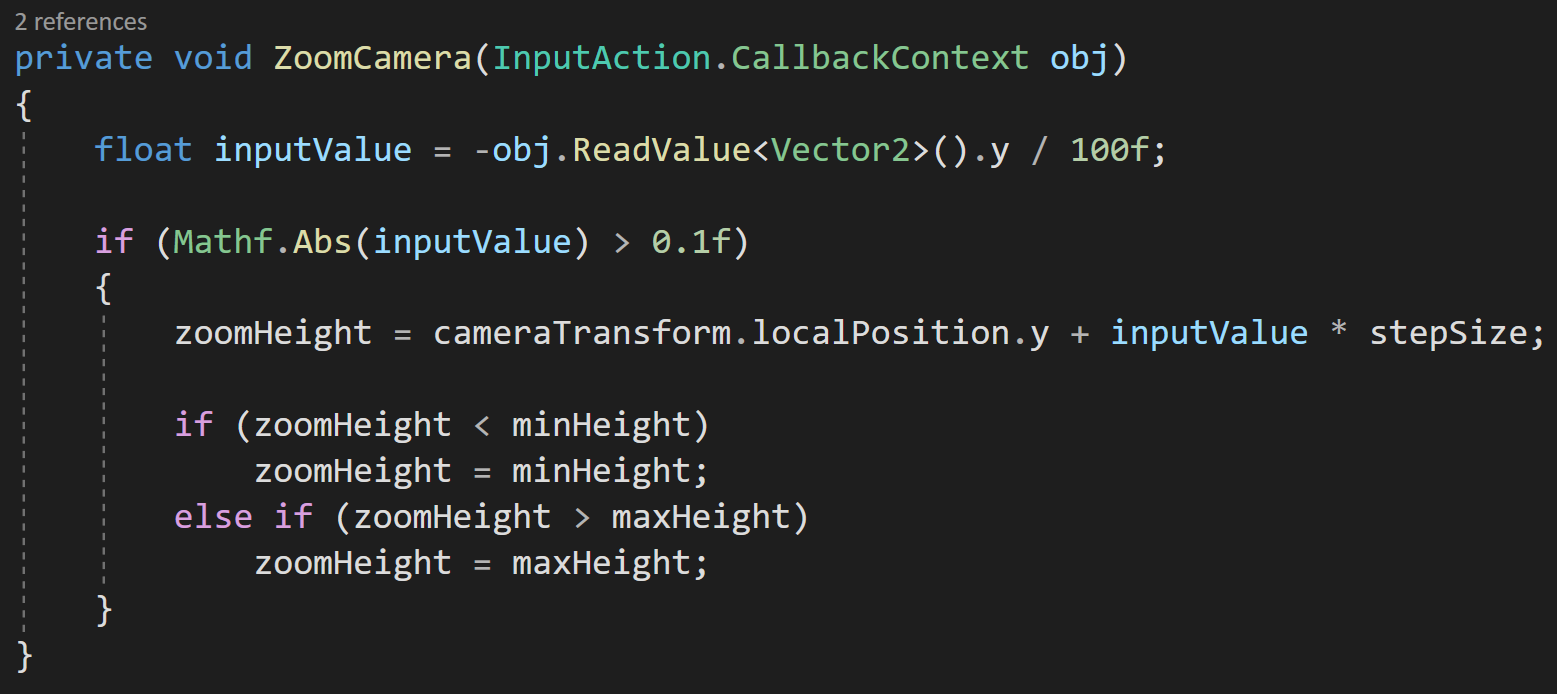
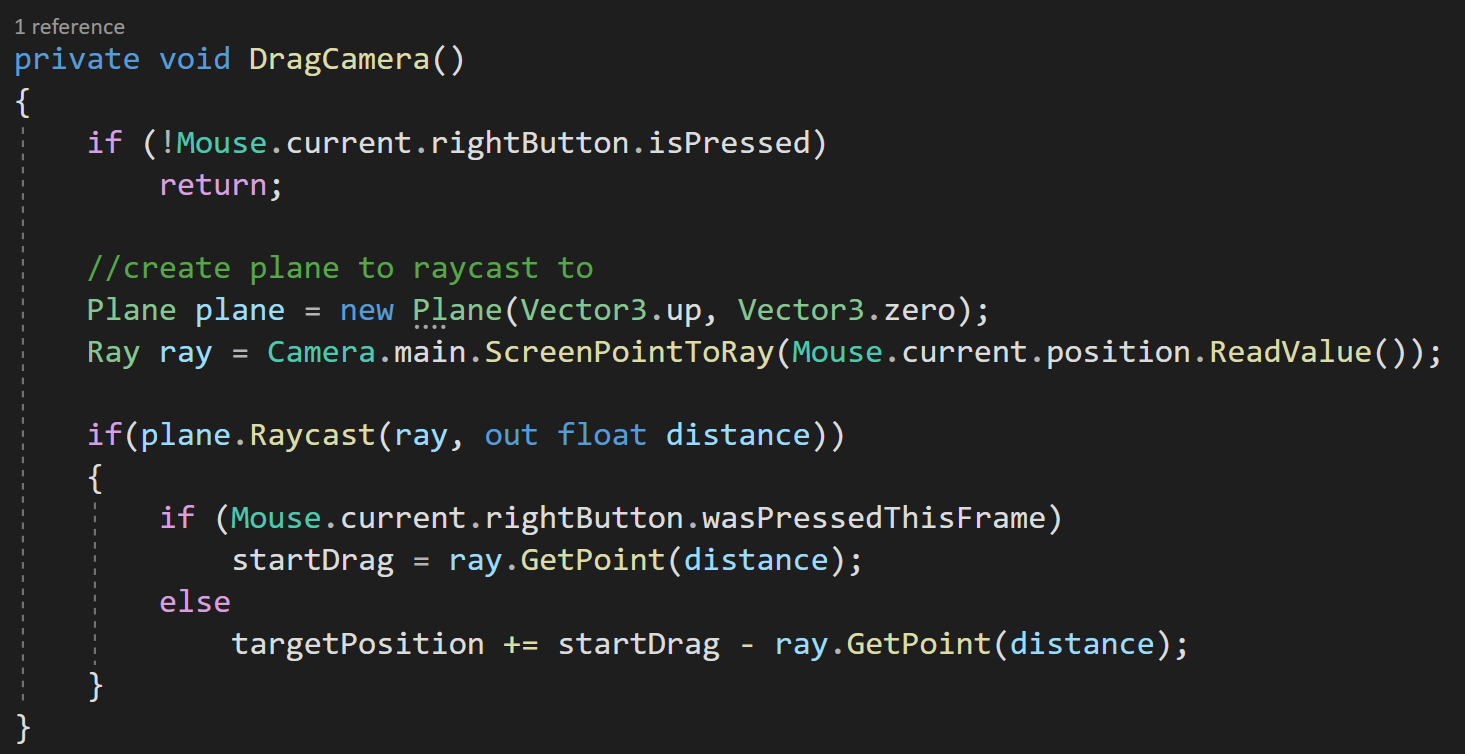
Inside the OnUpdateSelected function, we check if objectBeingPlaced is null, if it’s not then we want to move the object. To move it we’re going to do some raycasting. To keep things simple, I’ll create a plane and raycast against it. This limits the movement to the plane, but I think that’ll cover most use cases.
This is SO much simpler and cleaner than what I’ve done in the past.
If you haven’t seen the Plane class, I just discovered it a few weeks back, the plane is defined by a normal vector and a point on the plane. It also has a built in raycast function which is much simpler to use than the physics raycaster - albeit also more limited in functionality.
Double Click

How about a double click? There are a LOT of solutions out there that are way more complex than what appears to be needed. All kinds of coroutines, updates, variables…. You just don’t need it. Unity gives us a built-in way to register click count. So let’s make use of it.
The real star of the show in the code is the OnPointerClick function and the PointerEventData that is passed into the function. here all we need to do is check if eventData.clickCount is equal to 2. If it is then there was a double click.
Could it be much easier?
In addition, this should work with UI and scene objects (need a physics raycaster) equally well.
The rest of the code presented just adds a bit of juice and some player feedback. We cache the scale of the object in the Start function. Then when the pointer enters the object we tween the scale up and likewise when the pointer exits we tween the scale back down to its original size.
As a side note registering the double click did not work for me with the new input system version 1.0.2. An update to 1.3 fixed the issue. There was no issue with the “old input system.”
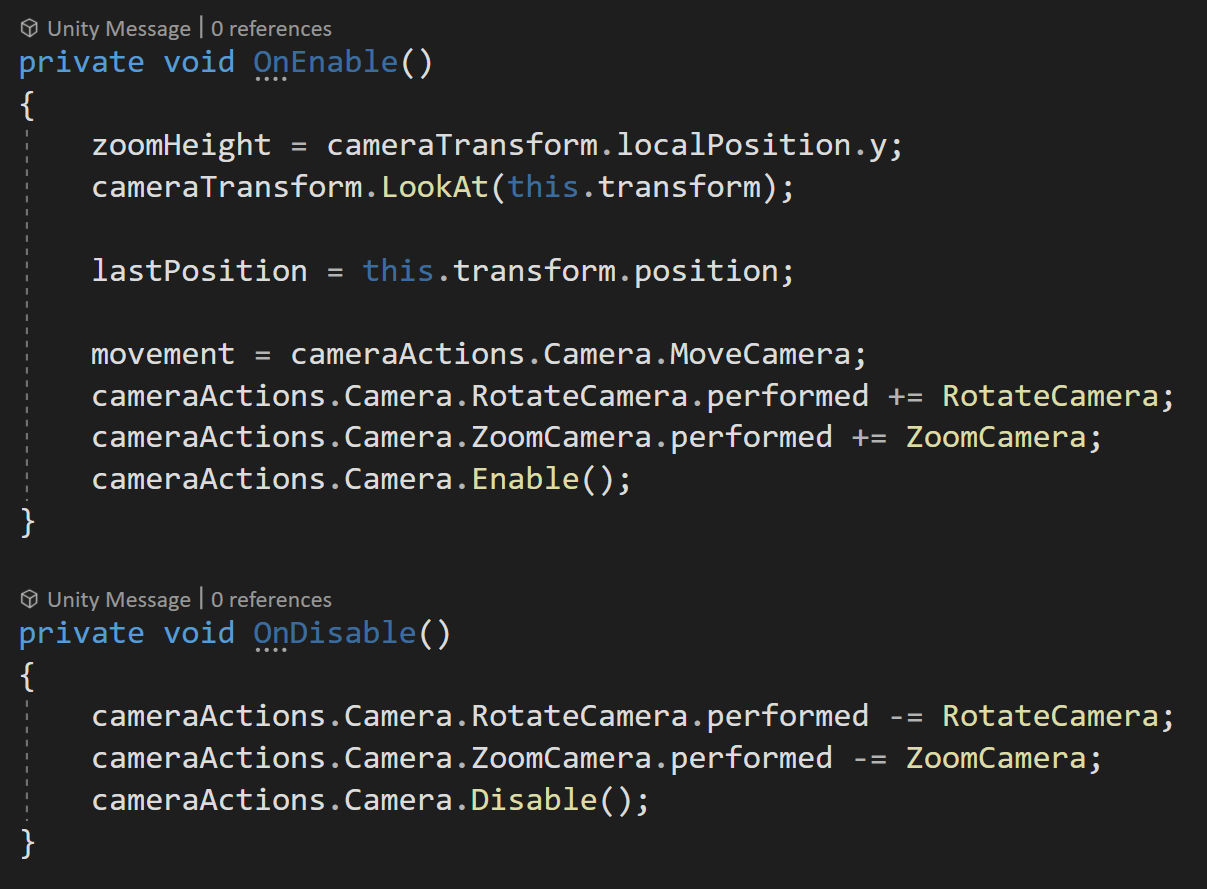
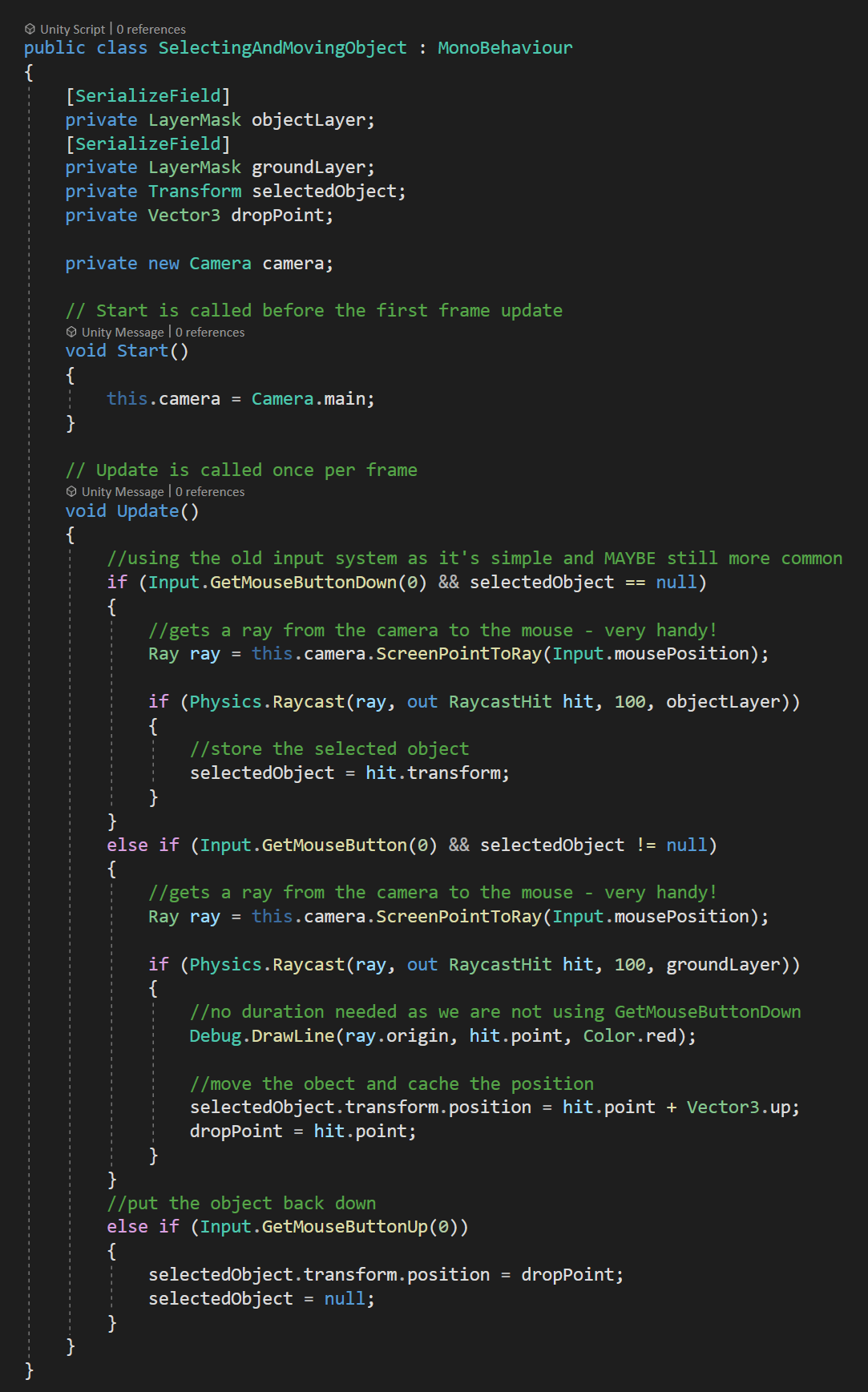
Moving Scene Objects

Okay, so what if you want to move an object around in the scene, but that object is already in the scene? This is very similar to the example above, however (in my experience) we need an extra step.
We need to set the selected gameObject - without doing this the OnUpdateSelected function will not get called as the event system doesn’t seem to automatically set a scene object as selected.
Setting the selected object needs to happen in the OnPointerDown function. Then in the OnPointerUp function, the selected object gets set to null - this prevents any unwanted interactions from the object still being the “selected” object.
The other bit that I’ve added is the OnCancel function (and interface). This gets invoked when the player presses the cancel button - which by default is set as the escape key. If this is pressed I return the gameObject to its starting location and again set the selected object to null. This is a “nice to have” and really easy to add.
Dragging UI Objects
Who doesn’t like a draggable window? Once again these are easy to create using a handful of event handlers.

hierarchyLet’s get right to the star of the show, which is the OnBeginDrag and OnDrag functions. When the drag begins we want to calculate an offset between the pointer and the location of the object. This prevents the object from “snapping onto the pointer” which doesn’t feel great doubly so if the object is large.
Next, we need to set the object to be the last sibling. Since UI objects are drawn in the order that they are in the hierarchy this helps to ensure the object being dragged is on top. If you have a more complex UI structure you may need to get more clever with this and change the parent transform as well (we do this a bit in the next example).
Then!
In the OnDrag function, we simply we simply set the position (excuse the typo - no need for the double transform call) to the position of the pointer minus the offset. And that’s all it takes to drag a UI object.
But! I did add a bit more juice. The OnPointEnter and OnPointer Exit functions tween the scale of the object to give a little extra feedback. Then in OnEndDrag I play a simple SFX to give yet a bit more polish.
Drag and Drop “Inventory”

There is a Unity package with this prefab in the Github repo (link at the top)
Creating a full inventory system is much more complicated than this example. BUT! This example should be a good foundation for the UI part of an inventory system or a similar system that allows players to move UI objects. That said this is definitely the most complex of all the examples and it requires two classes. One is on the moveable object and the other is on the slot itself.
The UI structure also requires a bit of setup to work. In my case, I’ve used a grid (over there —>) with white slots (image) to drop in an item. The slots themselves have a vertical layout group - this helps snap the item into place and makes sure that it fills the slot.

Basic Setup of the Inventory Slot Object

Inventory Slot Component
The slots also have the “Inventory Slot” component attached. This is the simpler of the two bits of code so let’s start there.
The inventory slot makes use of the IDropHandler interface. This requires the OnDrop function - which gets called when another object gets dropped on it. In this case, all we want to do is set the parent of the object being dragged to the slot it was dropped on. And thankfully our event data has a reference to the object being dropped - once again keeping things clean and simple.
There are a ton of edge cases that aren’t addressed with this solution and are beyond the scope of this tutorial. For example: Checking if the slot is full. Limiting slots to certain types of objects. Stacking objects…

Okay. Now the more complicated bit. The inventory tile itself. The big idea here is we want to drag the tile around, keep it visible (last sibling) and we need to toggle off the raycast target while dragging so that the inventory slot can register the OnDrop event. Also, if the player stops dragging the item and it’s not on top of an inventory slot then we’re going to send the item back to its starting slot.
At the top, there are two variables. The first tracks the offset between the item and the pointer, just like in the previous example. The second will track which slot (parent) the item started in.
Then OnBeginDrag, we set the starting slot variable, set the parent to the root object (canvas) and set this object to the last sibling. These last two steps help to keep the item visible and dragging above other UI objects. We then cache the offset and set the raycast target to false. This needs to be set to false to ensure that OnDrop is called consistently on the inventory slot - i.e. it only gets called if the raycast can hit the slot and isn’t blocked by the object being dragged.
An important note on the raycast target: RaycastTarget needs to be set to false for all child objects too. In my case, I turned this off manually in the text object - but if you have a more complex object a Canvas Group component can be used to toggle this property for all child objects.
Moving on to the OnDrag function, this looks just like the example above, where we set the position of the object to the pointer position minus the offset.
Finally, the OnEndDrag function is where we need to toggle the raycastTarget back on so that we can move it again later. Also now that the dragging has ended we want to see if the current parent of the item is an inventory slot. If it is - it’s all good - if not we want to set the parent back to the starting slot. Because of the vertical layout group setting the parent will snap the position of the item back to it’s starting position. It’s worth noting that OnEndDrag (item) gets called after OnDrop (slot) which is why this works.
Note: I also added a SFX to the OnEndDrag. This is optional and can be done in a lot of different ways.
Pointer Event Data
I had hoped to go into a bit more detail on the Pointer Event Data class, but this post is already feeling a bit long. That said there is a ton of functionality in that class that can make adding functionality to Event Handlers so much easier. I’d also argue that a lot of the properties are mostly self explanatory. So I’ll cut and paste the basic documentation with a link to the page here.
Properties
button The InputButton for this event.
clickCount Number of clicks in a row.
clickTime The last time a click event was sent.
delta Pointer delta since last update.
dragging Determines whether the user is dragging the mouse or trackpad.
enterEventCamera The camera associated with the last OnPointerEnter event.
hovered List of objects in the hover stack.
lastPress The GameObject for the last press event.
pointerCurrentRaycast RaycastResult associated with the current event.
pointerDrag The object that is receiving OnDrag.
ointerEnter The object that received 'OnPointerEnter'.
pointerId Identification of the pointer.
pointerPress The GameObject that received the OnPointerDown.
pointerPressRaycast Returns the RaycastResult associated with a mouse click, gamepad button press or screen touch.
position Current pointer position.
pressEventCamera The camera associated with the last OnPointerPress event.
pressPosition The screen space coordinates of the last pointer click.
rawPointerPress The object that the press happened on even if it can not handle the press event.
scrollDelta The amount of scroll since the last update.u
seDragThreshold Should a drag threshold be used?
Public Methods
IsPointerMovingIs the pointer moving.
IsScrollingIs scroll being used on the input device.
Inherited Members
Properties
used Is the event used?
currentInputModule A reference to the BaseInputModule that sent this event.
selectedObject The object currently considered selected by the EventSystem.
Public Methods
Reset Reset the event.
Use Use the event.