Dev Log
Designing a New Game - My Process

Some of my projects….
This is my process. It’s been refined over 8+ years of tinkering with Unity, 2 game jams, and 2 games published to Steam.
My goal with this post is just to share. Share what I’ve learned and share how I am designing my next project. My goal is not to suggest that I’ve found the golden ticket. Cause I haven’t. I’m pretty sure the perfect design process does not exist.
So these are my thoughts. These are the questions I ask myself as I stumble along in the process of designing a project. Maybe this post will be helpful. Maybe it won’t. If it feels long-winded. It probably is.
I’ve tried just opening Unity and designing as I go. It didn’t work out well. So again, this is just me sharing.
TL;DR
Set a Goal - To Learn? For fun? To sell?
Play games as research - Play small games and take notes.
Prototypes system - What don’t you know how to build? Is X or Y actually doable or fun?
Culling - What takes too long? What’s too hard? What is too complicated?
Plan - Do the hard work and plan the game. Big and small mechanics. Art. Major systems.
Minimal Viable Product - Not the game just the basics. Is it fun? How long did it take?
Build it! - The hardest part. Also the most rewarding.
What Is The Goal?
When starting a new project, I first think about the goal for the project. For me, this is THE key step in designing a project - which is a necessary step to the holy grail of actually FINISHING a project. EVERY other step and decision in the process should reflect back on the goal or should be seen through the lens of that goal. If the design choice doesn’t help to reach the goal, then I need to make a different decision.
Am I making a game to share with friends? Am I creating a tech demo to learn a process or technique? Am I wanting to add to my portfolio of work? What is the time frame? Weeks? Months? Maybe a year or two (scary)?

I want another title in this list!
For this next project, I want to add another game to the OWS Steam library and I’d like to generate some income in the process. I have no dreams of creating the next big hit, but if I could sell 1000 or 10,000 copies - that would be awesome.
I also want to do it somewhat quickly. Ideally, I could have the project done in 6 to 9 months, but 12 to 18 months is more likely with the time I can realistically devote to the project. One thing I do know, is that whatever amount of time I think it’ll take. It’ll likely take double.
Research!
After setting a goal, the next step is research. Always research. And yes. I mean playing games! I look for games that are of a similar scope to what I think I can make. Little games. Games with interesting or unique mechanics. Games made by individuals or MAYBE a team of 2 or 3. As I play I ask myself questions:
What elements do I find fun? What aspects do I not enjoy? Do I want to keep playing? What is making me want to quit? What mechanics or ideas can I steal? What systems do I know or not know how to make? Which systems are complex? What might be easy to add?
Then there are three more questions. These are key and crucial in designing a game and can help to keep the game scope (somewhat) in check. Which in turn is necessary if a game is going to get finished
How did a game developer’s clever design decisions simplify the design? How does a game make something fun without being complex? Why might the developer have made decisions X or Y? What problems did that decision avoid?
These last questions are tough and often have subtle answers. They take thought and intention. Often while designing a game my mind goes towards complexity. Making things bigger and more detailed! Can’t solve problem A? Well, lets bolt-on solution B!
For example, I’ve wanted to make a game where the player can create or build the world. Why not let the player shape the landscape? Add mountains and rivers? Place buildings? Harvest resources? It would be so cool! Right? But it’s a huge time sink. Even worse, it’s complex and could easily be a huge source of bugs.
So a clever solution? I like how I’m calling myself clever. Hex tiles. Yes. Hex tiles. Let the player build the world, but do it on a grid with prefabs. Bam! Same result. Same mechanic. Much simpler solution. It trades a pile of complex code for time spent in Blender designing tiles. Both Zen World and Dorf Romantic are great examples of allowing the player to create the world and doing so without undue complexity.
Navigation can be another tough nut to crack. Issues and bugs pop up all over the place. Units running into each other. Different movement costs. Obstacles. How about navigation in a procedural landscape? Not to mention performance can be an issue with a large number of units.
My “Research” List
Creeper World 4 gets around this in such a simple and elegant way. Have all the units fly in straight lines. Hover. Move. Land. Done.
I am a big believer that constraints can foster creativity. For me, identifying what I can’t do is more important than identifying what I can do.
When I was building Fracture the Flag I wanted the players to be able to claim territory. At first, I wanted to break the map up into regions - something like the Risk map. I struggled with it for a while. One dead end after another. I couldn’t figure out a good solution.
Then I asked, why define the regions? Instead, let the players place flags around the map to claim territory! If a flag gets knocked down the player loses that territory. Want to know if a player can build at position X or Y? They can if it’s close to a flag. So many problems solved. So much simpler and frankly so much more fun.
With research comes a flood of ideas. And it’s crucial to write them down. Grab a notebook. Open a google doc. Or as I recently discovered Google Keep - it’s super lightweight and easy to access on mobile for those ah-ha moments.
I keep track of big picture game ideas as well as smaller mechanics that I find interesting. I don’t limit myself to one idea or things that might nicely fit together. This is the throwing spaghetti at the wall stage of design. I’m throwing it out there and seeing what sticks. Even if, maybe especially if, I get excited about one idea I force myself to think beyond it and come up with multiple concepts and ideas. This is not the time to hyper focus.
At this stage, I also have to bring in a dose of reality. I’m not making an MMO or the next E-Sports tile. I’m dreaming big, but also trying not to waste my time with completely unrealistic dreams. I should probably know how to make at least 70, 80 or maybe 90 percent of the game!
While you’re playing games as “research” support small developers and leave them reviews! Use those reviews to process what you like and what you don’t like. What would you change? What would you keep? What feels good? What would feel better? Those reviews are so crucial to a developer. Yes, even negative ones are helpful.
Prototype Systems - Not The Game
At this point in the process, I get to start scratching the itch to build. Up until now, Unity hasn’t been opened. I’ve had to fight the urge, but it’s been for the best. Until now.
Now I get to prototype systems. Not a game or the game. Just parts of a potential game. This is when I start to explore systems that I haven’t made before or systems I don’t know how to make. I focus on parts that seem tricky or will be core to the game. I want to figure out the viability of an idea or concept.
At this stage, I dive into different research. Not playing games, but watching and reading tutorials and articles. I take notes. Lots of notes. For me, this is like going back to school. I need to learn how other people have created systems or mechanics. Why re-invent the wheel? Sometimes you need to roll your own solution, but why not at least see how other folks have done it first?
If I find a tutorial that feels too complex. I look for another. If that still feels wrong, I start to question the mechanic itself.
Maybe it’s beyond my skill set? Maybe it’s too complex for a guy doing this in his spare time? Or maybe I just need to slow down and read more carefully?
Some prototype Art for a possible Hex tile Game
Understanding and implementing a hex tile system was very much all of the above. Red Blob Games has an excellent guide to hex grids with all the math and examples of code to implement hex grids into your games. It’s not easy. Not even close. But it was fun to learn and with a healthy dose of effort, it’s understandable. (To help cement my understanding, I may do a series of videos on hex grids.)
This stage is also a chance to evaluate systems to see if they could be the basis of a game. I’ve been intrigued by ecosystems and evolution for a long while. Equilinox is a great example of a fairly recent ecosystem-based game made by a single (skilled) individual. Sebastian Lague put together an interesting video on evolution, which was inspired by the Primer videos. All of these made me want to explore the underlying mechanics.
So, I spent a day or two writing code, testing mechanics, and had some fun but ultimately decided it was too fiddly and too hard to base a game on. So I moved on, but it wasn’t a waste of time!
After each prototype is functional, but not polished, I ask myself more questions.
Does the system work? Is the system janky? What parts are missing or still need to be created? Is it too complex or hard to balance? Is there too much content to create? Or maybe it’s just crap?
For me, it’s also important that I’m not trying to integrate different system prototypes (at this point). Not yet. I for sure want to avoid coupling and keep things encapsulated, but I also don’t want to go down a giant rabbit hole. That time may come, but it’s not now. I’m also not trying to polish the prototypes. I want the systems to work and be reasonably robust, but at this point, I don’t even know if the systems will be in a game so I don’t want to waste time.
(Pre-Planning) Let The Culling Begin!
With prototypes of systems built, it’s now time to start chopping out the fluff, the junk, and start to give some shape to a game design. And yes, I start asking more questions.
What are the major systems of the game? What systems are easy or hard to make? Are there still systems I don’t know how to make? What do I still need to learn? What will be the singular core mechanic of the game?
And here’s a crucial question!
What are the time sinks? Even if I know how to do X or Y will it take too long?
3D Models, UI, art, animations, quests, stories, multiplayer, AI…. Basically, everything is a time sink. But!
Which ones play to my strengths? Which ones help me reach my goal? Which ones can I design around or ignore completely? What time sinks can be tossed out and still have a fun game?
Assets I Use
When I start asking these questions it’s easy to fall into the trap of using 3rd party assets to solve my design problems or fill in my lack of knowledge. It’s easy to use too many or use the wrong ones. I need to be very picky about what I use. Doubly so with assets that are used at runtime (as opposed to editor tools). For me, assets need to work out of the box AND work independently. If my 3rd party inventory system needs to talk to my 3rd party quest system which needs to talk to my 3rd party dialogue system I am asking for trouble and I will likely find it.
The asset store is full of shiny objects and rat holes. It’s worth a lot of time to think about what you really need from the asset store.
What you can create on your own? What should you NOT create on your own? What you can design around? Do you really need X or Y?
For me, simple is almost always better. If I do use 3rd party assets, and I do, they need to be part of the prototyping stage. I read the documentation and try to answer as many questions as I can before integrating the asset into my project. If the asset can’t do what I need, then I may have to make hard decisions amount the asset, my design, or even the game as a whole.
I constantly have to remind myself that games aren’t fun because they’re complex. Or at the very least, complexity does not equal fun. What makes games fun is something far more subtle. Complexity is a rat hole. A shiny object.
Deep Breath. Pause. Think.
At this point, I have a rough sketch in my head of the game and it’s easy to get excited and jump into building with both feet. But! I need to stop. Breathe. And think.
Does the game match my goals? Can I actually make the game? Are there mechanics that should be thrown out? Can I simplify the game and still reach my goal? Is this idea truly viable?
Depending on the answers, I might need be to go back and prototype, do more research, or scrap the entire design and start with something a single guy can actually make.
This point is a tipping point. I can slow down and potentially re-design the game or spend the next 6 months discovering my mistakes. Or worse, ignoring my mistakes and wasting even more time as I stick my head in the sand and insist I can build the game. I’ve been there. I’ve done that. And it wasn’t fun.
Now We Plan

Maybe a third of the items on my to do list for Grub Gauntlet
Ha! I bet you thought I was done planning. Not even close. I haven’t even really started.
There are a lot of opinions about the best planning tool. For me, I like Notion. Others like Milanote or just a simple google doc. The tool doesn’t matters, it’s the process. So pick what works for you and don’t spend too much time trying to find the “best” tool. There’s a poop ton of work to do, don’t waste time.
Finding the right level of detail in planning is tough and definitely not a waste of time. I’m not creating some 100+ page Game Design Document. Rather I think of what I'm creating as a to-do list. Big tasks. Small tasks. Medium tasks. I want to plan out all the major systems, all the art, and all the content. This is my chance to think through the game as a whole before sinking 100’s or likely 1000’s of hours into the project.
To some extent, the resulting document forms a contract with myself and helps prevent feature creep. The plan also helps when I’m tired or don’t know what to do next. I can pull up my list and tackle something small or something interesting.
Somewhere in the planning process, I need to decide on a theme or skin for the game. The naming of classes or objects may depend on the theme AND more importantly, some of the mechanics may be easier or harder to implement depending on the theme. For example, Creeper World 4’s flying tanks totally work in the sci-fi-themed world. Not so much if they were flying catapults or swordsmen in a fantasy world. Need to resupply units? Creeper World sends the resources over power lines. Again, way easier than an animated 3D model of a worker using a navigation system to run from point A to point B and back again.
Does the theme match the mechanics? Does it match my skillset? Can I make that style of art? Does the theme help reach the goal? Does the theme simplify mechanics or make them more complex?
Minimum Viable Product (MVP)
Upgrade that
Knowlegde

Finally! Now I get to start building the project structure, writing code, and bringing in some art. But! I’m still not building the game. I’m still testing. I want to get something playable as fast as possible. I need to answer the questions:

Is the game fun? Have I over-scoped the game? Can I actually build it with my current skills and available time?
If I spent 3 months working on an inventory system and all I can do is collect bits on a terrain and sell them to a store. I’ve over-scoped the game. If the game is tedious and not fun then I either need to scrap the game or dig deeper into the design and try to fix it. If the game breaks every time I add something or change a system then I need to rethink the architecture or maybe the scope of the game or upgrade my programming knowledge and skill set.
If I can create the MVP in less than a month and it’s fun then I’m on to something good!
Why so short a time frame? My last project, Grub Gauntlet was created during a 48-hour game jam. I spent roughly 20 hours during that time to essentially create an MVP. It then took another 10 months to release! I figure the MVP is somewhere around 1/10th or 1/20th of the total build time.
It’s way better to lose 1-2 months building, testing, and then decide to scrap the project than to spend 1-2 years building a pile of crap. Or worse! Spend years working only to give up without a finished product.
Can I Build It Now?
This is the part we’re all excited about. Now I get to build, polish, and finish a game. There’s no secret sauce. This part is the hardest. It’s the longest. It’s the most discouraging. It’s also the most rewarding.
If I’ve done my work ahead of time then I should be able to finish my project. And that? That is an amazing feeling!

Strategy Game Camera: Unity's New Input System
I was working on a prototype for a potential new project and I needed a camera controller. I was also using Unity’s “new” input system. And I thought, hey, that could be a good tutorial…
There’s also a written post on the New Input System. Check the navigation to the right.
The goal here is to build a camera controller that could be used in a wide variety of strategy games. And to do it using Unity’s “New” Input System.
The camera controller will include:
Horizontal motion
Rotation
Zoom/elevate mechanic
Dragging the world with the mouse
Moving when the mouse is near the screen edge
Since I’ll be using the New Input System, you’ll want to be familiar with that before diving too deep into this camera controller. Check either the video or the written blog post.
If you’re just here for the code or want to copy and paste, you can get the code along with the Input Action Asset on GitHub.
Build the Rig

Camera rig Hierarchy
The first step to getting the camera working is to build the camera rig. For my purposes, I choose to keep it simple with an empty base object that will translate and rotate in the horizontal plane plus a child camera object that will move vertically while also zooming in and out.
I’d also recommend adding in something like a sphere or cube (remove its collider) at the same position as the empty base object. This gives us an idea of what the camera can see and how and where to position the camera object. It’s just easy debugging and once you’re happy with the camera you can delete the extra object.

Camera object transform settings
For my setup, my base object is positioned on the origin with no rotation or scaling. I’ve placed the camera object at (0, 8.3, -8.8) with no rotation (we’ll have the camera “look at” the target in the code).
For your project, you’ll want to play with the location to help tune the feel of your camera.
Input Settings

Input Action Asset for the Camera Controller
For the camera controller, I used a mix of events and directly polling inputs. Sometimes one is easier to use than another. For many of these inputs, I defined them in an Input Action Asset. For some mouse events, I simply polled the buttons directly. If that doesn’t make sense hopefully it will.
In the Input Action Asset, I created an action map for the camera and three actions - movement, rotate, and elevate. For the movement action I created two bindings to allow the WASD keys and arrows keys to be used. It’s easy, so why not? Also important, both rotate and elevate have their action type set to Vector2.

Importantly the rotate action is using the delta of the mouse position not the actual position. This allows for smooth movement and avoids the camera snapping around in a weird way.
We’ll be making use of the C# events. So make sure to save or have auto-save enabled. We also need to generate the C# code. To do this select the Input Action Asset in your project folders and then in the inspector click the “generate C# class” toggle and press apply.

Variables and More Variables!
Next, we need to create a camera controller script and attach it to the base object of our camera rig. Then inside of a camera controller class we need to create our variables. And there’s a poop ton of them.
The first two variables will be used to cache references for use with the input system.
The camera transform variable will cache a reference to the transform with the camera object - as opposed to the empty object that this class will be attached to.
All of the variables with the BoxGroup attribute will be used to tune the motion of the camera. Rather than going through them one by one… I’m hoping the name of the group and the name of the variable clarifies their approximate purpose.

The camera settings I’m using
The last four variables are all used to track various values between functions. Meaning one function might change a value and a second function will make use of that value. None of these need to have their value set outside of the class.
A couple of other bits: Notice that I’ve also added the UnityEngine.InputSystem namespace. Also, I’m using Odin Inspector to make my inspector a bit prettier and keep it organized. If you don’t have Odin, you should, but you can just delete or ignore the BoxGroup attributes.
Horizontal Motion
I’m going to try and build the controller in chunks with each chunk adding a new mechanic or piece of functionality. This also (roughly) means you can add or not add any of the chunks and the camera controller won’t break.
The first chunk is horizontal motion. It’s also the piece that takes the most setup… So bear with me.
First, we need to set up our Awake, OnEnable, and OnDisable functions.
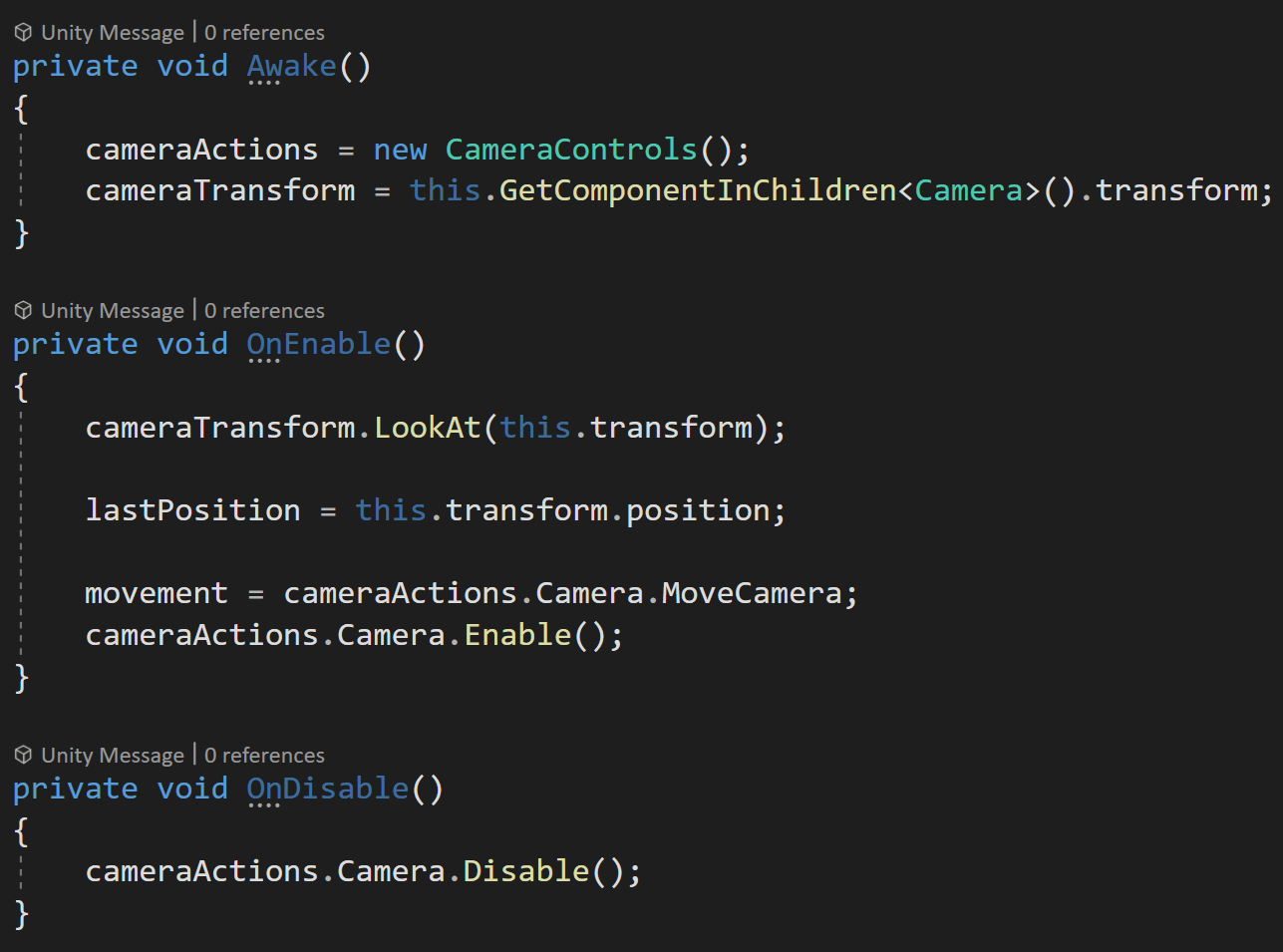
In the Awake function, we need to create an instance of our CameraControls input action asset. While we’re at it we can also grab a reference to the transform of our camera object.
In the OnEnable function, we first need to make sure our camera is looking in the correct direction - we can do this with the LookAt function directed towards the camera rig base object (the same object the code is attached to).
Then we can save the current position to our last position variable - this value will get used to help create smooth motion.
Next, we’ll cache a reference to our MoveCamera action - we’ll be directly polling the values for movement. We also need to call Enable on the Camera action map.
In OnDisable we’ll call Disable on the camera action map to avoid issues and errors in case this object or component gets turned off.

Helper functions to get camera relative directions
Next, we need to create two helper functions. These will return camera relative directions. In particular, we’ll be getting the forward and right directions. These are all we’ll need since the camera rig base will only move in the horizontal plane, we’ll also squash the y value of these vectors to zero for the same reason.

Kind of yucky. But gets the job done.
Admittedly I don’t love the next function. It feels a bit clumsy, but since I’m not using a rigidbody and I want the camera to smoothly speed up and slow down I need a way to calculate and track the velocity (in the horizontal plane). So thus the Update Velocity function.
Nothing too special in the function other than once again squashing the y dimension of the velocity to zero. After calculating the velocity we update the value of the last position for the next frame. This ensures we are calculating the velocity for the frame and not from the start.
The next function is the poorly named Get Keyboard Movement function. This function polls the Camera Movement action to then set the target position.
In order to translate the input into the motion we want we need to be a bit careful. We’ll take the x component of the input and multiply it by the Camera Right function and add that to the y component of the input multiplied by the Camera Forward function. This ensures that the movement is in the horizontal plane and relative to the camera.
We then normalize the resulting vector to keep a uniform length so that the speed will be constant even if multiple keys are pressed (up and right for example).

The last step is to check if the input value’s square magnitude is above a threshold, if it is we add our input value to our target position.
Note that we are NOT moving the object here since eventually there will be multiple ways to move the camera base, we are instead adding the input to a target position vector and our NEXT function will use this target position to actually move the camera base.
If we were okay with herky-jerky movement the next function would be much simpler. If we were using the physics engine (rigidbody) to move the camera it would also be simpler. But I want smooth motion AND I don’t want to tune a rigidbody. So to create smooth ramping up and down of speed we need to do some work. This work will all happen in the Update Base Position function.
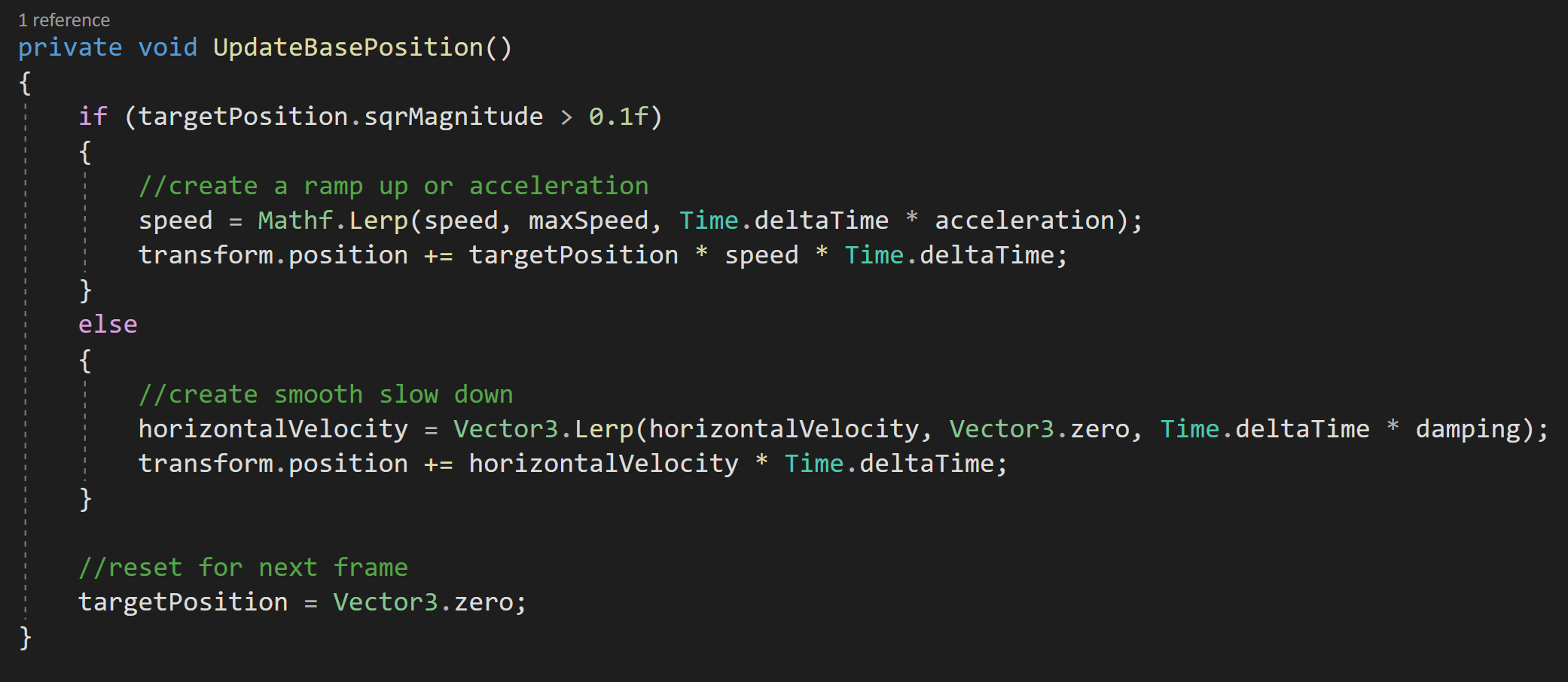
First, we’ll check if the square magnitude of the target position is greater than a threshold value. If it is this means the player is trying to get the camera to move. If that’s the case we’ll lerp our current speed up to the max speed. Note that we’re also multiplying Time Delta Time by our acceleration. The acceleration allows us to tune how quickly our camera gets up to speed.
The use of the threshold value is for two reasons. One so we aren’t comparing a float to zero, i.e. asking if a float equals zero can be problematic. Two, if we were using a game controller joystick even if it’s at rest the input value may not be zero.

Testing the Code so far - Smooth Horizontal Motion

We then add to the transform’s position an amount equal to the target position multiplied by the current camera speed and time delta time.
While they might look different these two lines of code are closely related to the Kinematic equations you may have learned in high school physics.
If the player is not trying to get the camera to move we want the camera to smoothly come to a stop. To do this we want to lerp our horizontal velocity (calculated constantly by the previous function) down to zero. Note rather than using our acceleration to control the rate of the slow down, I’ve used a different variable (damping) to allow separate control.
With the horizontal velocity lerping it’s way towards zero, we then add to the transform’s position a value equal to the horizontal velocity multiplied by time delta time.
The final step is to set the target position to zero to reset for the next frame’s input.
Our last step before we can test our code is to add our last three functions into the update function.
Camera Rotation

Okay. The hardest parts are over. Now we can add functionality reasonably quickly!
So let’s add the ability to rotate the camera. The rotation will be based on the delta or change in the mouse position and will only occur when the middle mouse button is pressed.
We’ll be using an event to trigger our rotation, so our first addition to our code is in our OnEnable and OnDisable functions. Here we’ll subscribe and unsubscribe the (soon to be created) Rotate Camera function to the performed event for the rotate camera action.

If you’re new to the input system, you’ll notice that the Rotate Camera function takes in a Callback Context object. This contains all the information about the action.

Rotating the camera should now be a thing!
Inside the function, we’ll first check if the middle mouse button is pressed. This ensures that the rotation doesn’t occur constantly but only when the button is pressed. For readability more than functionality, we’ll store the x value of the mouse delta and use it in the next line of code.
The last piece is to set the rotation of the transform (base object) and only on the y-axis. This is done using the x value of the mouse delta multiplied by the max rotation speed all added to the current y rotation.
And that’s it. With the event getting invoked there’s no need to add the function to our update function. Nice and easy.
Vertical Camera Motion
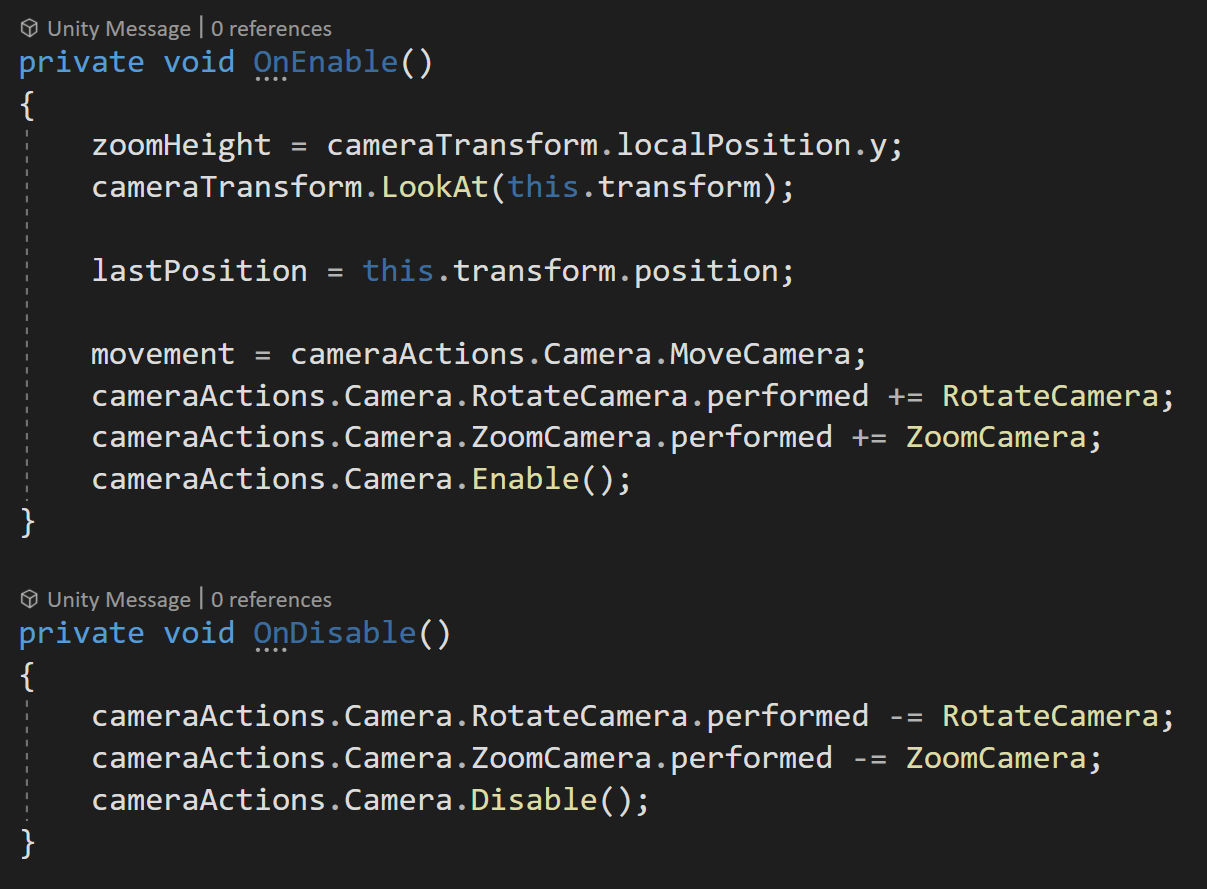
With horizontal and rotational motion working it would be nice to move the camera up and down to let the player see more or less of the world. For controlling the “zooming” we’ll be using the mouse scroll wheel.
This motion, I found to be one of the more complicated as there were several bits I wanted to include. I wanted there to be a min and max height for the camera - this keeps the player from zooming too far out or zooming down to nothingness - also while going up and down it feels a bit more natural if the camera gets closer or farther away from what it’s looking at.
This zoom motion is another good use of events so we need need to make a couple of additions to the OnEnable and OnDisable. Just like we did with the rotation we need to subscribe and unsubscribe to the performed event for the zoom camera action. We also need to set the value of zoom height equal to the local y position of the camera - this gives an initial value and prevents the camera from doing wacky things.
Then inside the Zoom Camera function, we’ll cache a reference to the y component of the scroll wheel input and divide by 100 - this scales the value to something more useful (in my opinion).
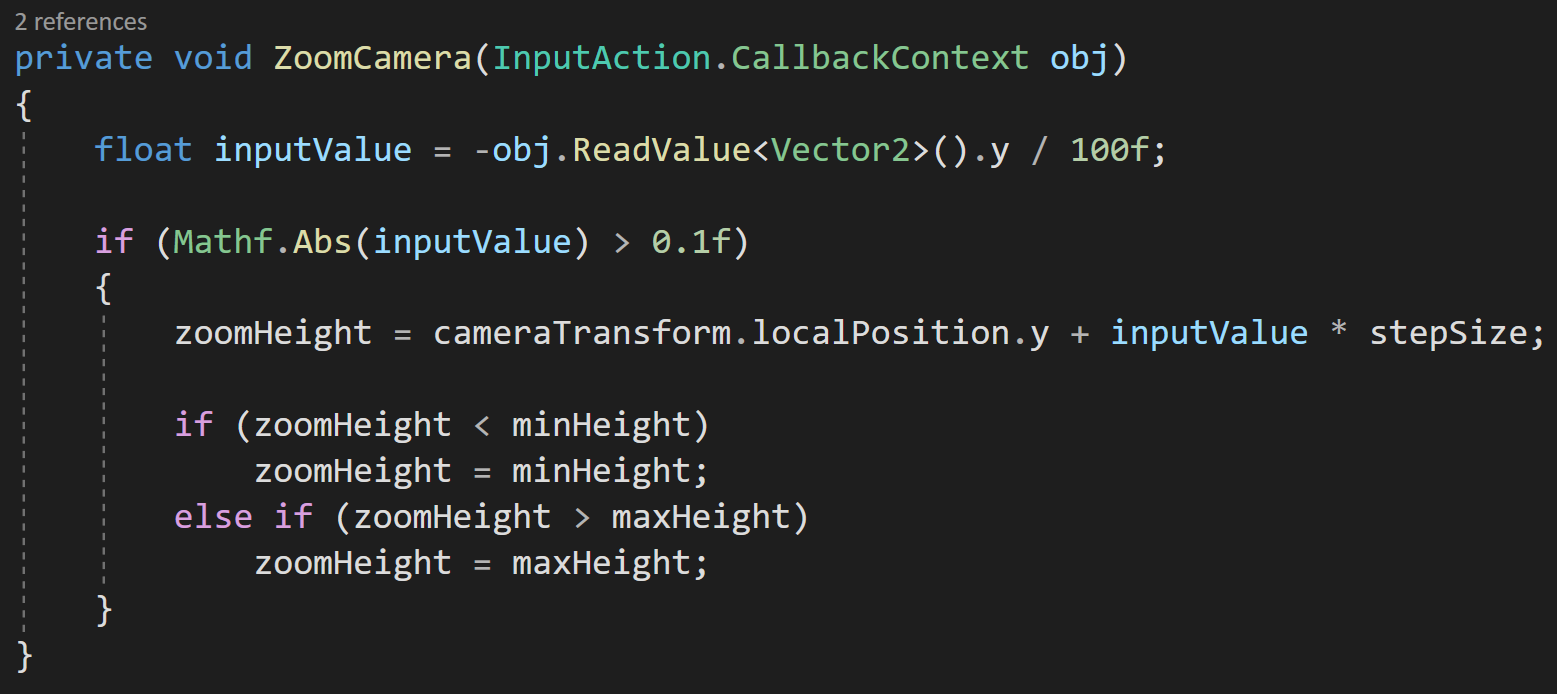
If the absolute value of the input value is greater than a threshold, meaning the player has moved the scroll wheel, we’ll set the zoom height to the local y position plus the input value multiplied by the step size. We then compare the predicted height to the min and max height. If the target height is outside of the allowed limits we set our height to the min or max height respectively.
Once again this function isn’t doing the actual moving it’s just setting a target of sorts. The Update Camera Position function will do the actual moving of the camera.
The first step to move the camera is to use the value of the zoom height variable to create a Vector3 target for the camera to move towards.


Zooming in action
The next line is admittedly a bit confusing and is my attempt to create a zoom forward/backward motion while going up and down. Here we subtract a vector from our target location. The subtracted vector is a product of our zoom speed and the difference between the current height and the target height All of which is multiplied by the vector (0, 0, 1). This creates a vector proportional to how much we are moving vertically, but in the camera’s local forward/backward direction.

Our last steps are to lerp the camera’s position from its current position to the target location. We use our zoom damping variable to control the speed of the lerp.
Finally, we also have the camera look at the base to ensure we are still looking in the correct direction.
Before our zoom will work we need to add both functions to our update function.
If you are having weird zooming behavior it’s worth double-checking the initial position of the camera object. My values are shown at the top of the page. In my testing if the x position is not zero, some odd twisting motion occurs.
Mouse at Screen Edges

At this point, we have a pretty functional camera, but there’s still a bit more polish we can add. Many games allow the player to move the camera when the mouse is near the edges of the screen. Personally, I like this when playing games, but I do find it frustrating when working in Unity as the “screen edges” are defined by the game view…

To create this motion with the mouse all we need to do is check if the mouse is near the edge of the screen.
We do this by using Mouse.current.position.ReadValue(). This is very similar to the “old” input system where we could just call Input.MousePosition.
We also need a vector to track the motion that should occur - this allows the mouse to be in the corner and have the camera move in a diagonal direction.

Screen edge motion
Next, we simply check if the mouse x and y positions are less than or great than threshold values. The edge tolerance variable allows fine tuning of how close to the edge the cursor needs to be - in my case I’m using 0.05.
The mouse position is given to us in pixels not in screenspace coordinates so it’s important that we multiply by the screen width and height respectively. Notice that we are again making use of the GetCameraRight and GetCameraForward functions.
The last step inside the function is to add our move direction vector to the target position.
Since we are not using events this function also needs to get added to our update function.
Dragging the World
I stole and adapted the drag functionality from Game Dev Guide.
The last piece of polish I’m adding is the ability to click and drag the world. This makes for very fast motion and generally feels good. However, a note of caution when implementing this. Since we are using a mouse button to drag this can quickly interfere with other player actions such as placing units or buildings. For this reason, I’ve chosen to use the right mouse button for dragging. If you want to use the left mouse button you’ll need to check if you CAN or SHOULD drag - i.e. are you placing an object or doing something else with your left mouse button. In the past I have used a drag handler… so maybe that’s a better route, but it’s not the direction I choose to go at this point.
I should also admit that I stole and adapted much of the dragging code from a Game Dev Guide video which used the old input system.
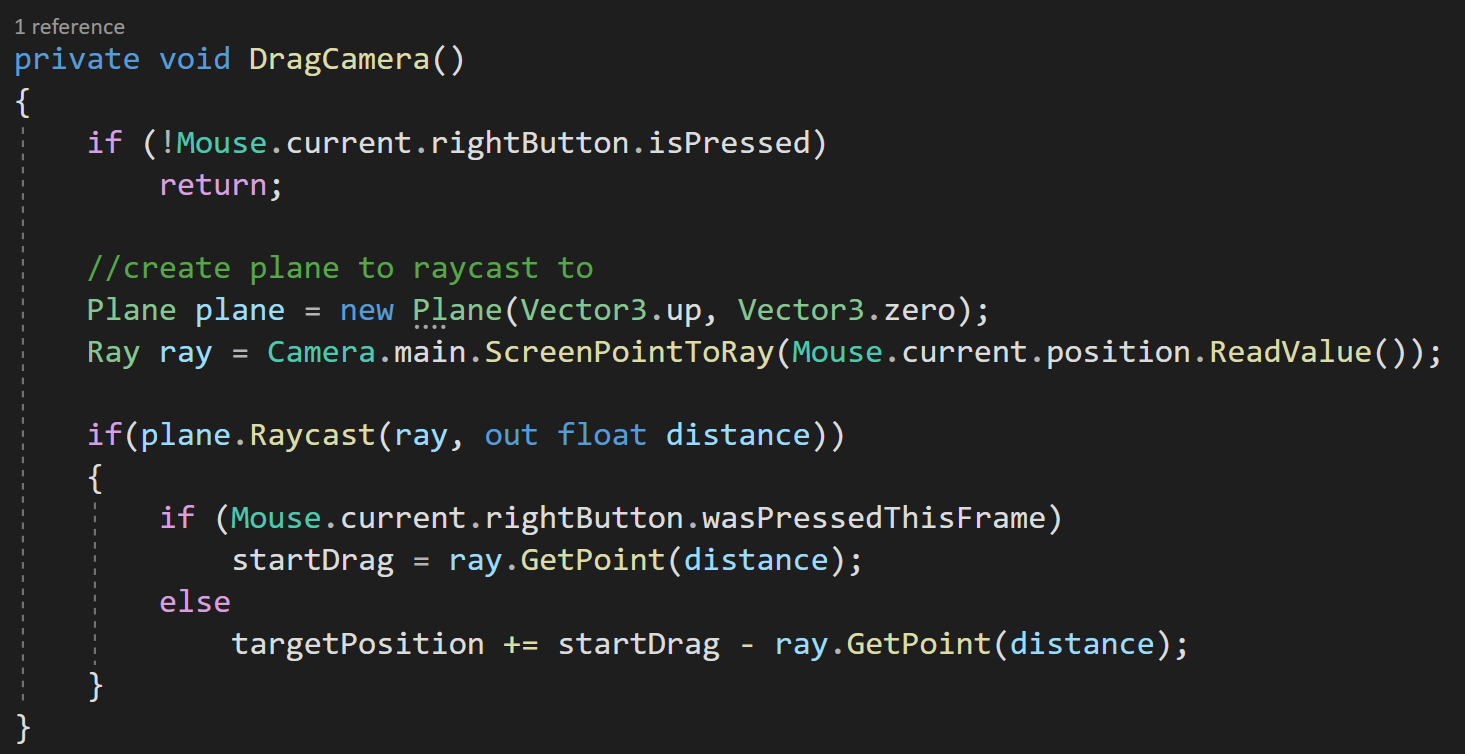
Since dragging is an every frame type of thing, I’m once again going to directly poll to determine whether the right mouse button is down and to get the current position of the mouse…
This could probably be down with events, but that seems contrived and I’m not sure I really see the benefit. Maybe I’m wrong.
Inside the Drag Camera function, we can first check if the right button is pressed. If it’s not we don’t want to go any further.

If the button is pressed, we’re going to create a plane (I learned about this in the Game Dev Guide video) and a ray from the camera to the mouse cursor. The plane is aligned with the world XZ plane and is facing upward. When creating the plane the first parameter defines the normal and the second defines a point on the plane - which for the non-math nerds is all you need.
Next, we’ll raycast to the plane. So cool. I totally didn’t know this was a thing!
The out variable of distance tells us how far the ray went before it hit the plane, assuming it hit the plane. If it did hit the plane we’re going to do two different things - depending on whether we just started dragging or if we are continuing to drag.

Dragging the world
If the right mouse button was pressed this frame (learned about this thanks to a YouTube comment) we’ll cache the point on the plane that we hit. And we get that point, by using the Get Point function on our ray.
If the right mouse button wasn’t pressed this frame, meaning we are actively dragging, we can update the target position variable with the vector from where dragging started to where it currently is.
The final step is to add the drag function to our update function.
That’s It!
There you go. The basics of a strategy camera for Unity using the New Input System. Hopefully, this gives you a jumping off point to refine and maybe add features to your own camera controller.

Raycasting - It's mighty useful
Converting the examples to use the new input system. Please check the pinned comment on YouTube for some error correction.

What is Raycasting?
Raycasting is a lightweight and performant way to reach out into a scene and see what objects are in a given direction. You can think of it as something like a long stick used to poke and prod around a scene. When something is found, we can get all kinds of info about that object and have access
So… It’s pretty useful and a tool you should have in your game development toolbox.
Three Important Bits
The examples here are all going to be 3D, if you are working on a 2D project the ideas and concepts are nearly identical - with the biggest difference being that the code implementation is a tad different.
It’s also worth noting that the code for all the raycasting in the following examples, except for the jumping example, can be put on any object in the scene, whether that is the player or maybe some form of manager.
The final and really important tidbit is that raycasting is part of the physics engine. This means that for raycasting to hit or find an object, that object needs to have a collider or a trigger on it. I can’t tell you how many hours I’ve spent trying to debug raycasting only to find I forgot to put a collider on an object.
But First! The Basics.

The basics Raycast function
We need to look at the Raycast function itself. The function has a ton of overloads which can be pretty confusing when you’re first getting started.
That said using the function basically breaks down into 5 pieces of information - the first two of which are required in all versions of the function. Those pieces of information are:
A start position.
The direction to send the ray.
A RaycastHit, which contains all the information about the object that was hit.
How far to send the ray.
Which layers can be hit by the raycast.
It’s a lot, but not too bad.

Defining a ray with start positon and the direction (both Vector3)

Raycast using a Ray
Unity does allow us to simplify the input para, just a bit, with the use of a ray. A ray essentially stores the start position and the direction in one container allowing us to reduce the number of input parameters for the raycast function by one.
Notice that we are defining the RaycastHit inline with the use of the keyword out. This effectively creates a local variable with fewer lines of code.
Ok Now Onto Shooting

Creating a ray from the camera through the center of the screen

To apply this to first-person shooting, we need a ray that starts at the camera and goes in the camera’s forward direction.
Then since the raycast function returns a boolean, true if it hits something, false if it didn’t, we can wrap the raycast in an if statement.
In this case, we could forgo the distance, but I’ll set it to something reasonable. I will, however, skip the layer mask as I want to be able to shoot at everything in the scene so the layer mask isn’t needed.
When I do hit something I want some player feedback so I’ll instantiate a prefab at the hit point. In my case, the prefab has a particle system, a light, and an audio source just to make shooting a bit more fun.

Okay, but what if we want to do something different when we hit a particular type of target?
There are several ways to do this, the way I chose was to add a script to the target (purple sphere) that has a public “GetShot” function. This function takes in the direction from the ray and then applies a force in that direction plus a little upward force to add some extra juice.
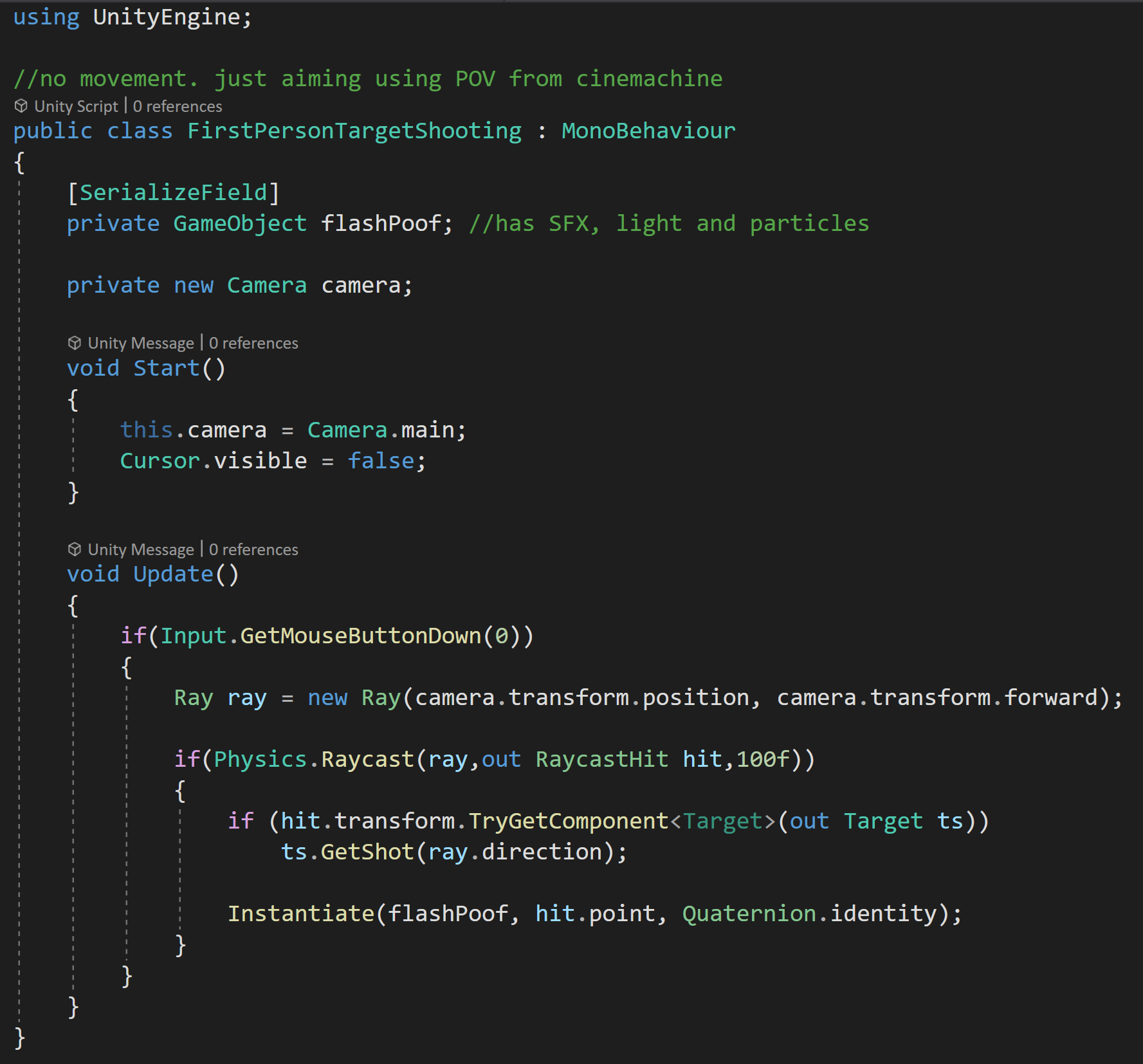
Complete first person shooting example
The unparenting at the end of the GetShot function is to avoid any scaling issues as the spheres are parented to the cubes below them.
Then back to the raycast, we can check if the object we hit has a “Target” component on it. If it does, we call the “GetShot” function and pass in the direction from the ray.
The function getting called could of course be on a player or NPC script and do damage or any other number of things needed for your game.
The RaycastHit gives us access to the object hit and thus all the components on that object so we can do just about anything we need.
But! We still need some way to trigger this raycast and we can do that by wrapping it all in another if statement that checks if the left mouse button was pressed. And all of that can go into our update function so we check every frame.
Selecting Objects

Another common task in games is to click on objects with a mouse and have the object react in some way. As a simple example, we can click on an object to change its color and then have it go back to its original color when we let go of the mouse button.
To do this, We’ll need two extra variables to hold references to a mesh renderer as well as the color of the material on that mesh renderer.
For this example, I am going to use a layer mask. To make use of the layer mask, I’ve created a new layer called “selectable” and changed the layer of all the cubes and spheres in the scene, and left the rest of the objects on the default layer. This will prevent us from clicking on the background and changing its color.
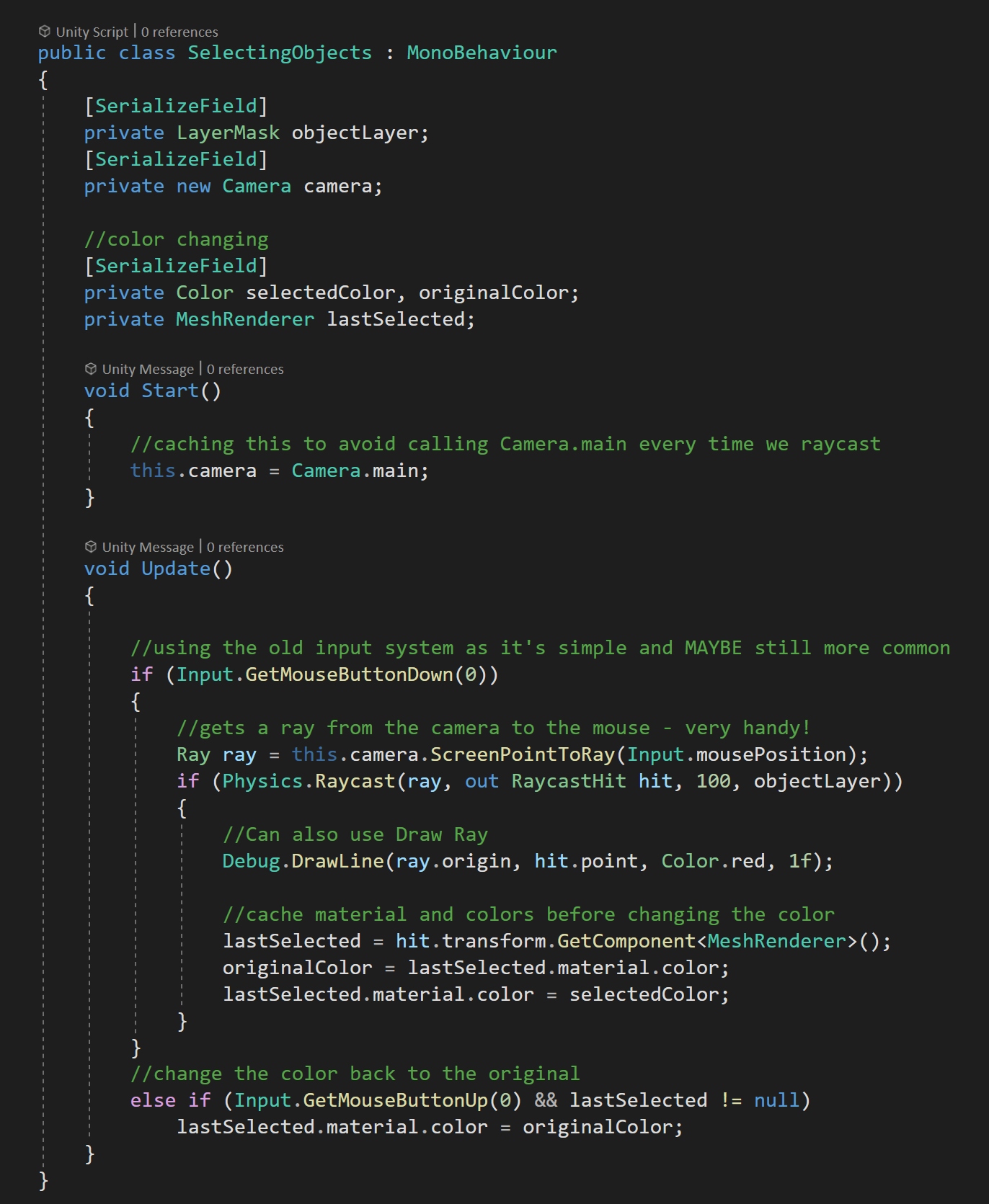
Complete code for Toggling objects color

Then in the script, I created a private serialized field of the type layer mask. Flipping back into Unity the value of the layer mask can be set to “selectable.”
Then if and else if statements check for the left mouse button being pressed and released, respectively.
If the button is pressed we’ll need to raycast and in this case, we need to create a ray from the camera to the mouse position.
Thankfully Unity has given us a nice built function that does this for us!
With our ray created we can add our raycast function, using the created ray, a RaycastHit, a reasonable distance, and our layer mask.
If we hit an object on our selectable layer, we can cache the mesh renderer and the color of the first material. The caching is so when we release the mouse button we can restore the color to the correct material on the correct mesh renderer.
Not too bad.
Notice that I’ve also added the function Debug.DrawLine. When getting started with raycasting it is SUPER easy to get rays going in the wrong direction or maybe not going far enough.
The DrawLine function does just as it says drawing a line from one point to another. There is also a duration parameter, which is how long the line is drawn in seconds which can be particularly helpful when raycasting is only done for one frame at time.
Moving Objects
Now at first glance moving objects seems very similar to selecting objects - raycast to the object and move the object to the hit point. I’ve done this a lot…
The problem is the object comes screaming towards the camera, because the hit point is closer to the camera than the objects center. Probably not what you or your players want to happen.


Don’t do this!!

One way around this is to use one raycast to select the object and a second raycast to move the object. Each raycast will use a different layer mask to avoid the flying cube problem.
I’ve added a “ground” layer to the project and assigned it to the plane in the scene. The “selectable” layer is assigned to all the cubes and spheres. The values for the layer masks can again be set in the inspector.
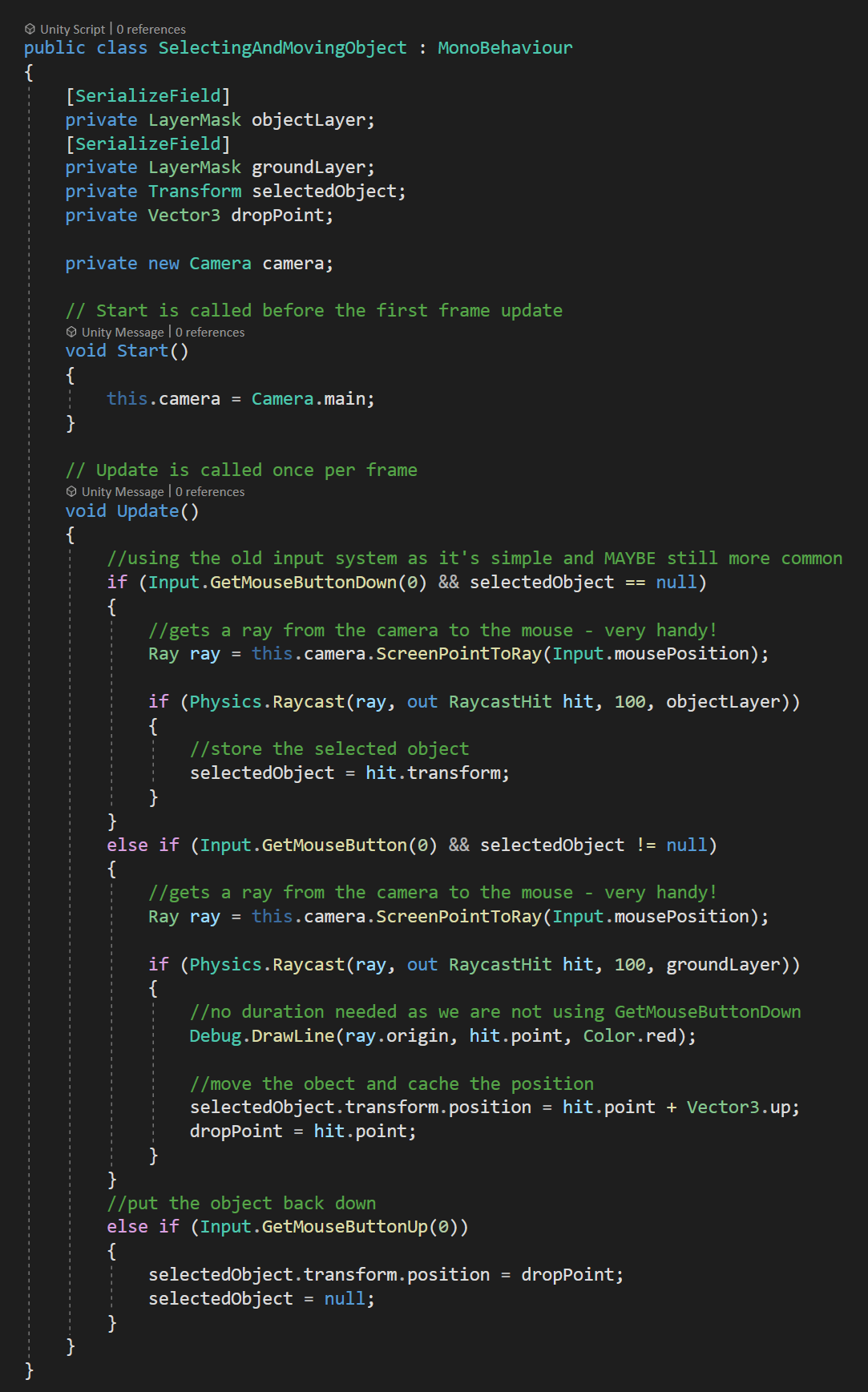
To make this all work, we’re also going to need variables to keep track of the selected object (Transform) and the last point hit by the raycast (Vector3).
To get our selected object, we’ll first check if the left mouse button has been clicked and if the selected object is currently null. If both are true, we’ll use a raycast just like the last example to store a reference to the transform of the object we clicked on.
Note the use of the “object” layer mask in the raycast function.
Our second raycast happens when the left mouse button is held down AND the selected object is NOT null. Just like the first raycast this one goes from the camera to the mouse, but it makes use of the second layer mask, which allows the ray to go through the selected object and hit the ground.
We now move the selected object to the point hit by the ray cast, plus for just for fun, we move it up a bit as well. This lets us drag the object around.
If we left it like this and let go of the mouse button the object would stay levitated above the ground. So instead, when the mouse button comes up we can set the position to the last point hit by the raycast as well as setting the selectedObject variable to null - allowing us to select a new object.
Jumping

The last example I want to go over in any depth is jumping, which can be easily extended to other platforming needs like detecting a wall or a slope or the edge of a platform - I’d strongly suggest checking out Sebastian Lague’s series on creating a 2D platformer if you want to see raycasting put to serious use not mention a pretty good character controller for a 2D game!
For this example, I’ve created a variable to store the rigidbody and I’ve cached a reference to that rigidbody in the start function.
For basic jumping, generally, the player needs to be on the ground in order to jump. You could use a trigger combined with OnTriggerEnter and OnTriggerExit to track if the player is touching the ground, but that’s clumsy and has limitations.
Instead, we can do a simple short raycast directly down from the player object to check and see if we’re near the ground. Once again this makes use of layer mask and in this case only casts to the ground layer.
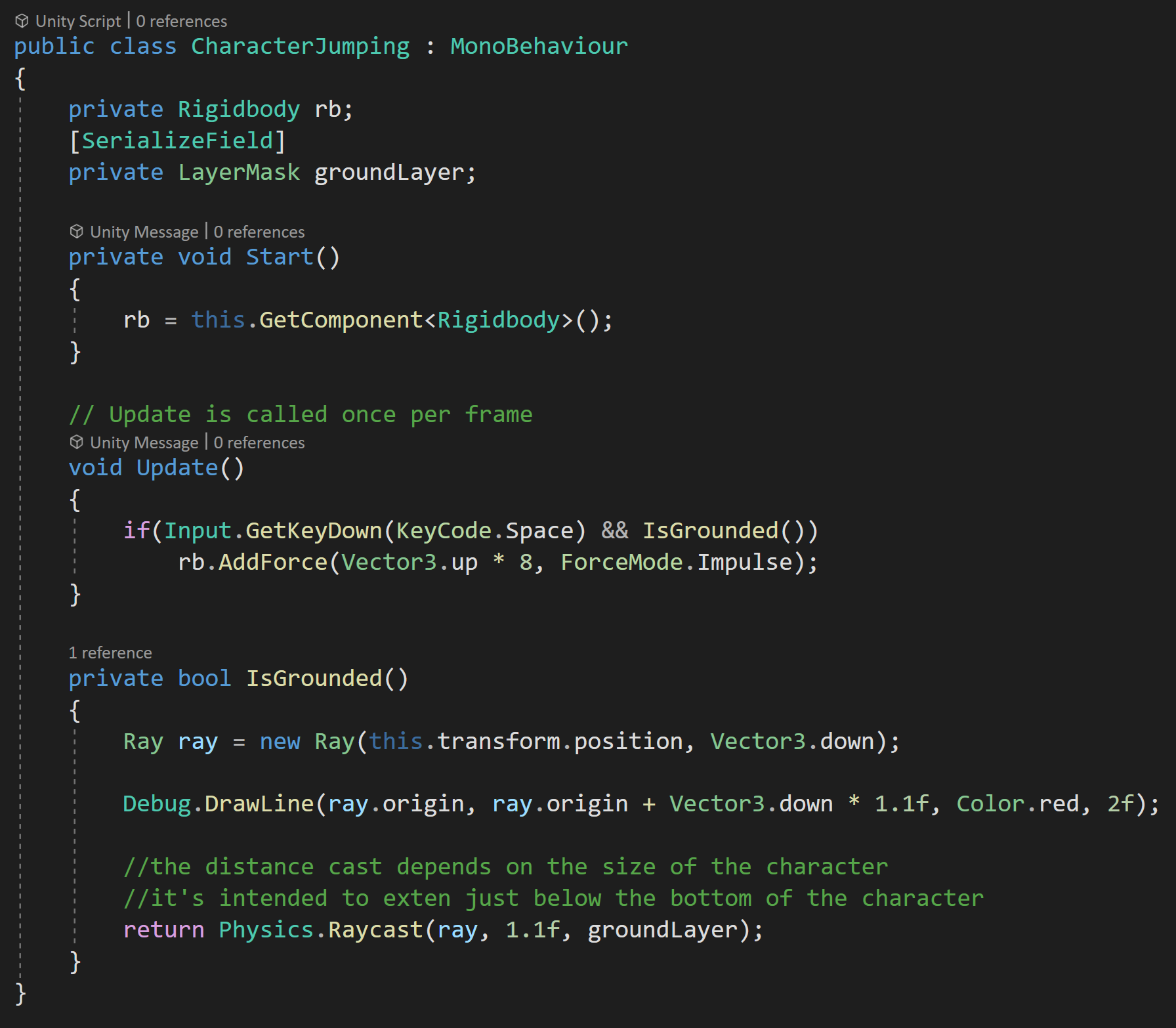
Full code for jumping
I’ve wrapped the raycast into a separate function that returns the boolean from the raycast. The ray itself goes from the center of the player character in the down direction. The raycast distance is set to 1.1 since the player object (a capsule) is 2 meters high and I want the raycast to extend just beyond the object. If the raycast extends too far, the ground can be detected when the player is off the ground and the player will be able to jump while in the air.
I’ve also added in a Debug.DrawLine function to be able to double-check that the ray is in the correct place and reaching outside the player object.
Then in the update function, we check if the spacebar is pressed along with whether the player is on the ground. If both are true we apply force to the rigidbody and it the the player jumps.
RaycastHit

The real star of the raycasting show is the RaycastHit variable.
It’s how we get a handle on the object the raycast found and there’s a decent amount of information that it can give us. In all the examples above we made use of “point” to get the exact coordinates of the hit. For me this is what I’m using 9 times out of 10 or even more when I raycast.
We can also get access to the normal of the surface we hit, which among other things could be useful if you want something to ricochet off a surface or if you want to have a placed object sit flat on a surface.
The RaycastHit can also return the distance from the ray’s origin to the hit point as well as the rigidbody that was hit (if there was one).
If you want to get really fancy you can also access bits about the geometry and the textures at the hit point.
Other Things Worth Knowing
So there’s 4 examples of common uses of raycasting, but there are a few other bits of info that could be good to know too.
There is an additional input for raycasting which is Physics.queriesHitTriggers. Be default this parameter is true and if its true raycasts will hit triggers. If it’s false the raycast will skip triggers. This could be helpful for raycasting to NPCs that have a collider on their body, but also have a larger trigger surrounding them to detect nearby objects.
Next useful bit. If you don’t set a distance for a raycast, Unity will default to an infinite distance - whatever infinity means to a computer… There could be several reasons not to allow the ray to go to infinity - the jump example is one of those.

A very non precise or accurate way of measures performance
Raycasting can get a bad rap for performance. The truth is it’s pretty lightweight.
I created a simple example that raycasts between 1 and 1000 times per frame. In an empty scene on my computer with 1 raycast I saw over 5000 fps. With a 1000 raycasts per FRAME I saw 800 fps. More importantly, but no more precisely measured, the main thread only took a 1.0 ms hit when going from 1 raycast to 1000 raycasts which isn’t insignificant, but it’s also not game-breaking. So if you are doing 10 or 20 raycasts or even 100 raycasts per frame it’s probably not something you need to worry about.

1 Raycast per Frame
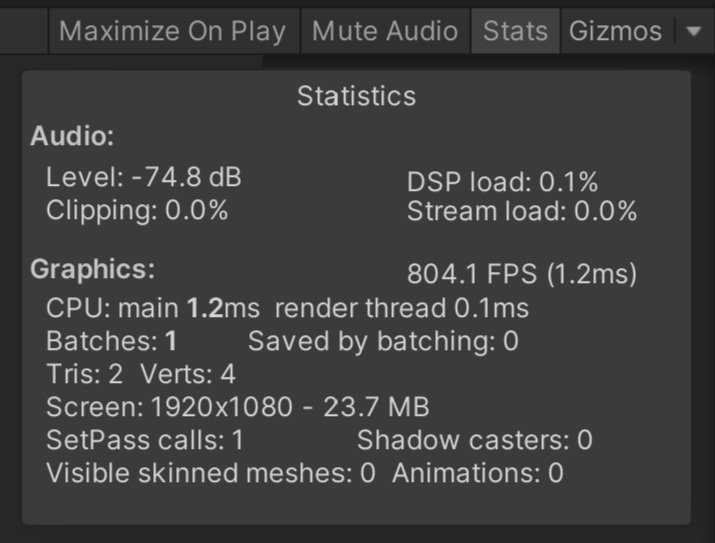
1000 Raycasts per Frame

Also worth knowing about, is the RaycastAll function. Which will return all objects the ray intersects, not just the first object. Definitely useful in the right situation.
Lastly, there are other types of “casting” not just raycasting. There is line casting, box casting, and sphere casting. All of which use their respective geometric shape and check for colliders and triggers in their path. Again useful in the right situation - but beyond the scope of this tutorial.

Older Posts
-
January 2026
- Jan 27, 2026 Save and Load Framework Jan 27, 2026
-
April 2024
- Apr 10, 2024 Ready for Steam Next Fest? - Polishing a Steam Page Apr 10, 2024
- Apr 1, 2024 Splitting Vertices - Hard Edges for Low Poly Procedural Generation Apr 1, 2024
-
November 2023
- Nov 18, 2023 Minute 5 to Minute 10 - Completing the Game Loop Nov 18, 2023
-
September 2023
- Sep 13, 2023 Visual Debugging with Gizmos Sep 13, 2023
-
July 2023
- Jul 4, 2023 Easy Mode - Unity's New Input System Jul 4, 2023
-
May 2023
- May 19, 2023 Level Builder - From Pixels to Playable Level May 19, 2023
-
April 2023
- Apr 11, 2023 Input Action in the Inspector - New Input System Apr 11, 2023
-
February 2023
- Feb 26, 2023 Tutorial Hell - Why You're There. How to Get Out. Feb 26, 2023
-
December 2022
- Dec 31, 2022 Upgrade System (Stats Part 2) Dec 31, 2022
-
November 2022
- Nov 10, 2022 Stats in Unity - The Way I Do it Nov 10, 2022
- Nov 5, 2022 State of UI in Unity - UI Toolkit Nov 5, 2022
-
August 2022
- Aug 17, 2022 Knowing When A Coroutine Finishes Aug 17, 2022
-
April 2022
- Apr 23, 2022 Unity Input Event Handlers - Or Adding Juice the Easy Way Apr 23, 2022
-
March 2022
- Mar 15, 2022 *Quitting a Job I Love Mar 15, 2022
-
February 2022
- Feb 8, 2022 Split Screen: New Input System & Cinemachine Feb 8, 2022
-
January 2022
- Jan 24, 2022 (Better) Object Pooling Jan 24, 2022
- Jan 19, 2022 Designing a New Game - My Process Jan 19, 2022
- Jan 16, 2022 Strategy Game Camera: Unity's New Input System Jan 16, 2022
-
December 2021
- Dec 16, 2021 Raycasting - It's mighty useful Dec 16, 2021
-
November 2021
- Nov 22, 2021 Cinemachine. If you’re not. You should. Nov 22, 2021
-
August 2021
- Aug 3, 2021 C# Extension Methods Aug 3, 2021
-
June 2021
- Jun 27, 2021 Changing Action Maps with Unity's "New" Input System Jun 27, 2021
-
May 2021
- May 28, 2021 Unity's New Input System May 28, 2021
- May 8, 2021 Bolt vs. C# - Thoughts with a dash of rant May 8, 2021
-
March 2021
- Mar 10, 2021 Coroutines - Unity & C# Mar 10, 2021
-
January 2021
- Jan 14, 2021 Where's My Lunch? - January Devlog Update Jan 14, 2021
-
December 2020
- Dec 27, 2020 C# Generics and Unity Dec 27, 2020
- Dec 7, 2020 Steam Workshop with Unity and Facepunch Steamworks Dec 7, 2020
-
November 2020
- Nov 27, 2020 Simple Level Save and Load System (Unity Editor) Nov 27, 2020
- Nov 9, 2020 Command Pattern - Encapsulation, Undo and Redo Nov 9, 2020
-
October 2020
- Oct 28, 2020 GJTS - Adding Steamworks API and Uploading Oct 28, 2020
- Oct 9, 2020 Game Jam... Now What? Oct 9, 2020
-
August 2020
- Aug 16, 2020 Strategy Pattern - Composition over Inheritance Aug 16, 2020
-
July 2020
- Jul 24, 2020 Observer Pattern - C# Events Jul 24, 2020
- Jul 15, 2020 Object Pooling Jul 15, 2020
- Jul 3, 2020 Cheat Codes with Unity and C# Jul 3, 2020
-
June 2020
- Jun 16, 2020 The State Pattern Jun 16, 2020
-
August 2019
- Aug 12, 2019 Easy UI Styles for Unity Aug 12, 2019
-
July 2019
- Jul 3, 2019 9th Grade Math to the Rescue Jul 3, 2019
-
June 2019
- Jun 12, 2019 Introducing My Next Game (Video DevLog) Jun 12, 2019
-
May 2019
- May 29, 2019 Programming Challenges May 29, 2019
-
March 2019
- Mar 2, 2019 Something New - Asking "What Can I Learn?" Mar 2, 2019
-
November 2018
- Nov 30, 2018 A Growing Channel and a New Tutorial Series Nov 30, 2018
-
October 2018
- Oct 11, 2018 Procedural Spaceship Generator Oct 11, 2018
-
July 2018
- Jul 11, 2018 Implementing SFX in Unity Jul 11, 2018
-
May 2018
- May 31, 2018 Prototyping Something New May 31, 2018
-
April 2018
- Apr 17, 2018 When to Shelve a Game Project? Apr 17, 2018
-
February 2018
- Feb 9, 2018 State of the Game - Episode 3 Feb 9, 2018
-
December 2017
- Dec 16, 2017 State of the Game - Episode 2 Dec 16, 2017
-
November 2017
- Nov 7, 2017 The Bump From A "Viral" Post Nov 7, 2017
-
October 2017
- Oct 30, 2017 NPC Job System Oct 30, 2017
-
September 2017
- Sep 1, 2017 Resources and Resource Systems Sep 1, 2017
-
August 2017
- Aug 3, 2017 State of the Game - Episode 1 Aug 3, 2017
-
June 2017
- Jun 20, 2017 Resources: Processing, Consumption and Inventory Jun 20, 2017
- Jun 15, 2017 Energy is Everything Jun 15, 2017
-
May 2017
- May 16, 2017 Graphing Script - It's not exciting, but it needed to be made May 16, 2017
- May 2, 2017 Tutorials: Low Poly Snow Shader May 2, 2017
-
April 2017
- Apr 28, 2017 Low Poly Snow Shader Apr 28, 2017
- Apr 21, 2017 Environmental Simulation Part 2 Apr 21, 2017
- Apr 11, 2017 Environmental Simulation Part 1 Apr 11, 2017
-
March 2017
- Mar 24, 2017 Building a Farming Game Loop and Troubles with Ground Water Mar 24, 2017
-
February 2017
- Feb 25, 2017 The Inevitable : FTF PostMortem Feb 25, 2017
-
December 2016
- Dec 7, 2016 Leaving Early Access Dec 7, 2016
-
November 2016
- Nov 28, 2016 Low Poly Renders Nov 28, 2016
- Nov 1, 2016 FTF: Testing New Features Nov 1, 2016
-
October 2016
- Oct 27, 2016 Watchtowers - Predictive Targeting Oct 27, 2016
- Oct 21, 2016 Click to Color Oct 21, 2016
- Oct 19, 2016 Unity Object Swapper Oct 19, 2016
-
September 2016
- Sep 18, 2016 Testing Single Player Combat Sep 18, 2016
-
May 2016
- May 25, 2016 Release Date and First Video Review May 25, 2016
-
March 2016
- Mar 26, 2016 Getting Greenlit on Steam Mar 26, 2016